中文输入法从万"码"奔腾到"无码"称雄
――中文信息处理技术的应用
郑 方 2003/11/25
1980年代初的时候,曾经有人预言中文的输入问题将阻碍计算机在中国的推广和应用。十余年过去了,中文输入不但没有成为问题,相反地,中文语言处理技术成为国内外研究的热点之一。由美国自然科学基金会(NSF)、美国国防高级研究规划局(DARPA)和美国国防部(DoD)资助,美国著名学府Johns
Hopkins University(http://www.clsp.jhu.edu/workshops/)负责承办和组织的语音和语言处理技术研讨会,每年都有来自全球的语音和语言研究机构及企业向其提交前沿的研究课题。研讨会经过严格的竞争和选拔,最终投票选出三到四个项目,然后再从全球著名的大学和公司招募顶尖的技术人员,进行为期8周的合作研发,以期对一些前沿研究课题提出一些新的思路和方法。这样的研讨会已经进行了约十年,能够被选入的项目无不被认为代表了全球的研究方向,能够被选中的人员都意味着获得很大的荣誉。
在历年为数不多的被选项目中,有关中文语音和语言处理内容的项目就有三次:2000年有两次,其中之一是作者作为高级成员参与的项目,项目的目标是口语中文语音识别,另外一个是关于中文和英文信息获取方面的;在2003年,作者提出的中文方言普通话的语音识别课题被选中。同时,著名的跨国公司都投入了大量的人力和物力从事中文语音和语言技术的研发,其中比较著名的有Microsoft、IBM、Intel、Nokia、Panasonic、Motorola等等。这表明不但中文不是计算机发展的"障碍",反而中文已经成为计算机处理的"热点"。
这些成就,应该归功于那些兢兢业业、默默无闻中文语音和语言处理研究工作者的坚定信念和辛苦劳动,其中早期的中文输入法更是起到了不可忽视的作用。
1. 汉语语言和汉字的特点
不同于西方语言,汉语的句法相当灵活,汉语本质上是一种意合语言等。它的语法结构没有西方语言那么严格,重在意会。一句话可能没有完整的主谓宾结构,却可以表达完整的语义,给人一幅清晰的图画;汉语中语序的灵活性有时让学习汉语的外国人一时摸不着头脑。如"吃食堂"可能是"吃于食堂"的简称或"在食堂吃饭"的倒装;如"天空中飘着一朵白云"的主语不是"天空"而是"白云"。而有些语义的灵活性也令人费解,说某某人"是东西"和"不是东西"都不行,说甲队"大胜"乙队和甲队"大败"乙队都是甲队赢。这些都给中文信息处理(中文的语言理解)带来一定的难度。关于这方面作者将另文讨论。
就中文输入法而言,更关心的是与字、音相关的问题。
1.1 汉语的音节和汉字
中文是一种音节性比较强的语言。汉语的音节(Syllable)表示读音,按照1958年2月11日全国人民代表大会通过的汉语拼音方案,音节用拼音(Pinyin)和数字(调,Tone)表示。汉语音节具有典型的声韵结构,也就是说,每个音节通常由声母(Initial)和韵母(Final)组成。汉语标准普通话中有22个声母,38个韵母。这些声韵母可以组成418个有效的无调音节,除去一些不常用的外,计算机常用的一般有408个音节。汉语有4个调和一个轻声调,有效的有调音节共有1,300个左右。汉语的声韵结构也有一些例外,如有的音节没有声母,只有韵母,这样的音节我们称之为零声母音节。例如/er/、/ya/、/wen/等;也有的音节是由某些辅音单独组成音节的,如/m/、/n/、/ng/等。
在汉语中,调的特征比西方语言更明显,因为调的不同会导致意义的不同,甚至完全相反,如"买/mai3/"和"卖/mai4/"仅一调之差。
汉语的汉字表形,常用于书写。国家标准的一二级字库共有6,700多个简化汉字。
在汉语中,通常一个字对应一个音节,就是说,在任何一个特定的句子中,每个汉字的读音是固定的,可以由一个唯一的有调音节表示。在一些不常见的情形下也有一些例外,比如上海话中把"勿要"两个字读成一个音节/fiao4/,当然这个音节在标准普通话中已越来越少用了。又比如"哈尔滨"通常读成两个音节/har
bin/而不是三个音节/ha er bin/。在一些儿话(Retroflexed)音中,有些词是必读儿化的,比如说"小孩儿/xiao hair/"、"花儿/huar/",……等。有一些特殊的字(通常为外来字)则一个字对应两个读音,如"瓩/qian1
wa3/(同'千瓦')"、"哩/ying1 li3/"、"浬/hai2 li3/"等等。在这些特定的情形下,这种一一对应关系稍有不同。
1.2 同音字(词)
如前所述,汉语一二级字库有6,700多个,而汉语音节数目只有1,300多个(有调)或400多个(无调)。因此必然会有多个字共用一个音的问题――即同音字。
著名的语言学家赵元任曾经分别用同一个音/yi/的汉字和同一个音/shi/的汉字写过两个故事,读来颇有意思。
/yi/
漪姨倚椅,悒悒,疑异疫,宜诣医。医以宜以蚁胰医姨。亿蚁殪,蚁胰溢。医以亿蚁溢胰医姨,姨疫以医。姨怡怡,以夷衣贻医。医衣夷衣,亦怡怡。噫!医以蚁胰医姨疫,亦异矣;姨以夷衣贻医,亦益异已矣!
/shi/
石室诗士施氏,嗜狮,誓食十狮。施氏时时适市视狮。十时,适十狮适市。是时,适施氏适市。施氏视是十狮,恃矢势,使是十狮逝世。施氏拾是十狮,适石室。石室湿,施氏使侍拭石室。石室拭,施氏始试食是十狮尸,食时,始识是狮尸,实十石狮尸。试释是事。
注:在紫光输入法中,读同一个音/yi/的汉字有319个,而读同一个音/shi/的汉字有195个。
汉语中的同音词现象也比较明显。下面给出几个二音节的同义词的例子:
/mai/ 买,卖
/shi li/ 实力,示例,实例,视力
/qing jie/ 清洁,情节,轻捷,情结
/shang wu/ 上午,晌午,商务,尚无,尚武
/ji shu/ 技术,级数,奇数,基数,记述,积数,计数
/zhi dao/ 知道,指导,直到,直捣,制导,之道,执导,致悼
/yi fu/ 衣服,姨父,姨夫,义夫,义父,依附,一幅,一副,一拂
/you yu/ 由于,忧郁,有余,鱿鱼,优于,优育,友渔,优裕,犹豫
同音词现象在三四字词及更长的词中不多见。
1.3 多音字
虽然常用汉字的数目比拼音的个数多,但汉语还存在多音字现象,即一字多音。汉语多音字按有调音节考虑,可以多达七八个,如"嗯/en4/、/en0/、/n2/、/n3/、/n4/、/ng2/、/ng3/、/ng4/"和"呵/a1/、/a2/、/a3/、/a4/、
/a0/、/he1/、/ke1/"等;而即使按无调音节考虑,也有三四个之多,
如,"差/cha/、/chai/、/ci/"和"哪/na/、/nai/、/ne/、/nei/"等。
汉语中的多音词现象则比较罕见。
不过相比较而言,在中文信息处理尤其是输入法中多音字问题不如同音字(词)问题那么重要,因为多音字问题只有在"字转音"的过程中才会碰到。
1.4 词的定义和分词问题
我们可能都读过中国古代文人骚客之间斗智的故事。在古代,中文是没有标点的,写出一段话"下雨天留客天留我不留",把标点加在不同的位置就会有不同的意义:
原 话: 下 雨 天 留 客 天 留 我 不 留
断句1: 下 雨 天,留 客。天 留,我 不 留!
断句2: 下 雨 天,留 客 天,留 我 不?留!
西方语言的词有严格的定义,一般在两个词之间会有空格分离,或用标点分离。而在汉语中,标点符号的使用正式开始于二十世纪一二十年代(最早使用新式标点的杂志是著名的《新青年》,1908年5
月号)。标点符号更多的是在"意群"一级给出分割,因此即使有了标点符号,在"词"一级汉语还存在很大的问题。我们使用Google等搜索引擎进行搜索时,常常会得到这种由于分词带来的令人啼笑皆非的结果。我们想搜索"索引",却发现"搜索引擎"也出来了。如"美国会……"可以解读为"美国|会……"也可以解读为"美|国会……"等。
导致这个问题的根本原因是中文对词没有严格的定义,在这个问题上许多语言学家还有很多争论。中文的词不但有词边界的歧义问题(如上文的例子),而且还有词的嵌套问题(如"中国"、"人民"、"中国人民")。另外一些词加一些后缀字"家"、"者"、"子"、"儿"、"长"、"们"、"徒"……等等是否称为词?一些词按某种规则形成的(如"高兴"变成"高高兴兴""高兴高兴"、"愿意"变成"愿不愿意")是否称为词?对这些问题不同人有不同的观点。
人名和地名等专有名词的自动检测也是中文信息处理必须面临的主要问题之一。
1.5 汉字的笔划
1965年中华人民共和国文化部和中国文字改革委员会发布《印刷通用汉字字形表》。国家语委、国家新闻出版署在1988年发布《现代汉语通用字表》,规定了汉字的字形结构、笔画数和笔顺。国家语言文字工作委员会和国家新闻出版署对《现代汉语通用字表》确定的笔顺进行了调整和完善,于1997年4月7日联合发布《现代汉语通用字笔顺规范》。教育部国家语言文字工作委员会于2001年12月19日发布(2002年03月31日实施)GB13000.1字符集汉字折笔规范(Chinese
Character Turning Stroke Standard of GB 13000.1 Character Set) GF2001-2001。
规范中规定,构成楷书汉字字形的最小单位是笔画(Stroke),笔画的形状称为笔形(Stroke feature)。汉字最基本的笔形有五种,其依次为横(一)、竖(丨)、撇(丿)、点(丶)和折(乙),称为主笔形(Basic
stroke feature),分别用序号1、2、3、4、5表示;与主笔形对应的从属笔形(除撇外的主笔形都有相对应的从属笔形),称为附笔形(Subordinate
stroke feature)。汉字附笔形中,提归于横,竖钩归于竖,捺归于点,多种曲折的折笔笔形归于折。
规范同时规定了汉字笔画的基本顺序,"先左后右,先上后下,先外后内,先中间后两边",又如:点在上边或左上边的要先写,点在右边(含右上方)或字里面的要后写;以"匠字框"(匚,也叫"三框")为部首的字,先写上边的一横,再写里面,最后写"竖折";
以"凶字框"(凵)为部首的字,先写里面,再写凶字框;……等。规范还给出了一些特殊字的笔画顺序。
许多汉字编码方法都是以笔形为出发点的。然而汉字中具有相同偏旁的汉字很多,如以"木"起笔的汉字就有400多个,含有"木"的汉字就更多了。这些因素导致很多汉字编码方案无法顾及汉语通用字笔顺规范,只能根据汉字的字型使用一些"拆字"的技巧,给使用者的使用带来不便。
2. 万"码"奔腾的时代
在中文输入法的历史上,曾经有过万"码"奔腾的时代。汉字编码研究工作者们花费了大量的心血研究汉字的编码方法:有的利用汉字的字形特征,有的利用汉字的笔画笔顺特征,有的利用汉字的拼音,有的把字形和读音结合起来等等,不一而足,从而提出了大量的汉字计算机输入方法。其中具有代表性的是五笔、郑码、自然码等。在这诸多的输入法中,有的符合国家规范(拼音或笔画笔顺),有的则不符合国家规范。不管怎么样,这些编码方法为中文的汉字计算机输入法做出了贡献,为中文信息处理做出了贡献。
随着国家规范的出台,在以用户为最终裁判的现实情况下,存活下来的输入法已经不多,屈指可数。然而无线通讯技术的发展和中文短信的巨大市场潜力,又使得新一轮的输入法大战拉开了序幕。
基于数字键盘的输入法所面临的最大挑战是只有10个数字键再加上"*"和"#"等键。手机键盘上的主流汉字输入法有两种。一种是利用笔画:利用国家规范规定的五个基本笔画,有的还辅以其他自定义笔画,如"口"、"八"、"小"等等,然后利用某种拆字方法进行编码。另外一种是利用拼音:根据数字小键盘上各个数字对应的字母关系,键入拼音。在数字小键盘上,这种数字和字母的对应关系是标准的,如下:
1 2 (abc) 3(def)
4(ghi) 5(jkl) 6(mno)
7(pqrs) 8(tuv) 9(wxyz)
* 0 #
比如需要输入拼音"zhong"是,按"9999 44 666 66 4",然后在许多同音字列表中选中想输入的字即可。T9输入法则把上面的数字键系列简化为"94664"。
不管是PC上的输入法还是手机或电话上的输入法,大多都是基于字的,即一个字一个字地输入,其中免不了需要在众多的重码汉字中进行挑选。好的汉字编码方法可以减少重码汉字的平均个数。为了减少用户的击键次数,有的输入法提供了基于词的输入方案,或者提供了词联想的模式,使得用户一旦输入了一个汉字,其后续的可能汉字就会马上显示出来,用户可以"一"键输入。
基于汉字编码的输入法中,很多可以达到很高的输入效率,然而一个最大问题是学习困难,非专业打字的用户要学会拆字,需要花费很长的时间。另外一个问题是,有的输入法不符合国家规范,这对小学生、中学生等而言是不合适的。
3. "无码"称雄的时代
"无码"并非指没有编码,事实上任何一种输入法都需要内部的编码。这里所谓的"无码"指的是不用国家规范编码以外的任何编码。比如利用拼音输入,那么就使用汉语拼音规范;如果利用笔画输入,就使用汉语笔画规范和通用字笔顺规范,不仅笔画符合规范,而且笔顺也符合规范。这样的输入法对用户而言最大的方便之处在于无需学习,会写字,按笔画顺序就可以输入;会读字,按拼音即可以输入。输入过程是在一种自然流畅的过程中完成的。当然,为了提高鲁棒性,可以允许某些特殊字兼容一些常见的错误笔顺。也可以允许一些模糊音,比如/zh/-/z/、/ch/-/c/、/sh/-/s/等。
一些常用的"无码"输入法包括:智能ABC、紫光拼音、微软拼音、拼音加加等。这类输入法无需学习的便利性形成了输入法中的一道独特的风景线。
为了方便用户,这类输入法通常有以下一个或几个特性:全拼、双拼、不完整拼音、中英文混拼、模糊音、带调拼音、词(联系)方式、用户自造词、高频先见、字(词)频自动调节等等。
尽管这些输入法提供了很多很好的功能,但最多还是基于词(词组)方式的,无法针对整个句子进行输入。整句输入法是否可能呢?
答案是肯定的。比较常见的有智能狂拼、黑马,以及得意输入法(http://www.d-ear.com/gifts/ime_palm/Register.htm)等。其中智能狂拼和黑马等输入法是PC平台的整句拼音输入法,而得意输入法则有PC平台、PDA平台、手机平台等的整句拼音输入法和整句笔画输入法。
中文整句输入法目前还不为大多数用户所接受,但相信用户会慢慢喜欢的。原因是:(1)它兼容词/词组方式输入;(2)用户无需象字词输入那样从众多候选中一个一个地挑选,做得好的输入法几乎可以不用用户选就直接输入整个句子;(3)在输入和选择比较困难的小型设备上,整句输入法更有优势;……
整句输入法的基本思路是利用上下文信息,技术上实现则利用了一种称为N-Gram的概率模型。
3.1 N-Gram模型
N-Gram是大词汇连续语音识别中常用的一种语言模型,对中文而言,我们称之为汉语语言模型(CLM, Chinese Language Model)。汉语语言模型利用上下文中相邻词间的搭配信息,在需要把连续无空格的拼音、笔划,或代表字母或笔划的数字,转换成汉字串(即句子)时,可以计算出具有最大概率的句子,从而实现到汉字的自动转换,无需用户手动选择,避开了许多汉字对应一个相同的拼音(或笔划串,或数字串)的重码问题。
最常用的CLM是称为Tri-gram(三元组)的语言模型,它给出了任意三个汉语词a、b和c之间的搭配概率P(c|a, b)。当已经有海量的汉语文本时,通过简单的计数方法,可以统计出任意三个词之间的搭配次数,从而估算出其搭配概率。这可以用于在把拼音串、笔划串或数字串到汉字转换过程中,从众多的候选当中根据最大似然的原则挑选出最好的候选。当从汉字的特征表达串(如拼音串、数字串或者笔划串)映射到适当的汉字串时,最大似然准则意味着最大概率。在Tri-gram语言模型中,汉字序列的出现概率以以下公式表示:
P(w1, w2, ..., wN) = P(w1) P(w2|w1) P(w3|w1,w2) ... P(wN|w1, w2, ...,
wN-1)
= P(w1) P(w2|w1) P(w3|w1,w2) P(w4|w2,w3)...P(wN|wN-2, wN-1)
= P(w1) P(w2|w1) ∏n (n=3,...,N) P(wn|wn-2, wn-1)
符号∏n (n=3,...,N) P(...) 表示概率的连乘。其中三元组(wN-2,wN-1, wN)出现的概率,也就是P(wn|wn-2,
wn-1),是从海量汉语文本(称为训练文本)中学习来的。
一般来说,N-Gram模型就是假设当前词的出现概率只同它前面的N-1个词有关,或者说它是用前N-1个词的出现概率去预测当前词的出现概率。常用的N-Gram模型有uni-Gram
(N=1、一元组)、bi-Gram(N=2、二元组)和tri-Gram(N=3、三元组)。
3.2 N-Gram模型的关键问题
使用N-Gram汉语语言模型时有这样一些关键问题需要解决:
(i) 对未曾出现的三元组的进行概率估计
中文中常用的词大约有50,000个或更多。任意三个词组成的三元组的数目就达到50,000 x 50,000 x 50,000 = 1.3 x
10^14规模,这其中有些三元组是不可能出现的,有些是很少出现的。因此,不管训练用的语料有多大,总会有一些三元组(a,b,c)不会在语料中出现。如果对这些三元组的概率不做特殊处理,将导致这些三元组的估计概率P(c|a,b)为0,从而导致句子的概率为0。但是,这些没有在训练语料中找到的三元组并不表示它们的出现概率为0,而是说它们出现的概率相对要小一点。因此这些三元组应该赋予相对较小的合理概率,而且不同的三元组应该根据具体情况赋予不同的概率。但如何估计呢?一般的解决方法是根据低阶的二元组概率P(c|b)去估计,这就是回退(Back-off)算法。回退算法是可以递归的,即如果P(c|b)还为0概率,则进一步回退到P(c)。为了保证概率总和为1,必须从那些非零概率的三元组的概率中折扣出来一些概率值,在未出现三元组中进行重新分配。
北京得意音通技术有限责任公司的得意输入法在这个问题上采取了更先进的技术,即双向回退估计,当P(c|a,b)为0时,用P(c|b)和P(b|a)去估计。这是得意公司的专利技术,利用这个技术可以使得概率估计更加准确。
(ii) 压缩模型存储空间
正如(i)中所说,Tri-gram语言模型在存储上十分巨大,因为即使大部分的三元组都没有出现,那些出现的三元组的存放也需要非常巨大的空间。通常情况下,一个词表大小为50K的中文语言模型需要300M到1G字节的空间用于存储。在PC机等具有大量存储的设备上可以不压缩模型存储空间;但存储量只有几十兆字节甚至更小的设备上应用是不实际的。这有两个方面的原因,一方面显然是因为存储空间,另一方面则是由于存储巨大造成的搜索过程耗时很大。得意公司之所以能够在PDA、手机等小型设备上实现中文整句输入法,是因为其专利技术采取了三个手段进行了有效的模型压缩:(1)只保存关键的一元组、二元组和三元组,其余用回退算法估计;(2)一元组的概率值用对数压缩技术存储从而所用bit数很少;(3)对保留下来的二元组概率值使用量化算法进行存储,只记录排序名次而不记录具体的数值,并通过索引树解决快速存取问题。利用这些技术,模型规模压缩到1MB以内,而模型精度(首选字精度)仍高于95%。
(iii) 进行解码或搜索
搜索的目的是将汉字的特征表达串(如拼音串或者笔画串)映射到汉字序列上,并且根据最大似然准则找到匹配最佳的序列作为最后的结果。因为(1)多个汉字共享一个笔划序列或拼音序列;(2)中文句子中,词之间没有明确的词边界;(3)一个句子由于切分点的不同而可以划分成不同的词序列(只有一个最合适),因此在从特征表达串映射到单个字,进而映射到句子的过程中,会产生很多符合匹配的"句子"。在这种情况下,我们不可能列出所有可能的汉字序列并进行概率比较。因此,一个高效而且准确的搜索算法就显得非常的重要。
得意公司的专利技术 (http://www.d-ear.com/Technologies&Products/Products-d-Ear%20IME_ch.htm)使用了一种音节同步的高效搜索算法,使得解码速度很快,脱机测试每秒中可以转换300多个汉字。高效的算法为得意输入法可以在Palm、Nokia9210等这样的嵌入式设备上实现中文整句输入法提供了有力的保障。
这种中文语言处理技术不但可以用在基于拼音和笔画的输入法中,而且可以用在基于手写体汉字识别的输入法中,使得用户不用逐字选择就可以快速进行整句输入。当然中文语言模型也可以应用在其他的中文信息处理领域中。
3.3 语义分析
上述所说大部分输入法,如果是基于拼音的,一般都使用无调拼音。正如第一节所谈,汉语的调有时会影响到解码出来的句子的意义,甚至导致完全相反的意义。在这种情况下,单靠N-Gram这样的概率模型是不能解决问题的。虽然可以用带调的拼音进行汉字输入,但那会给用户带来很多不便。一种较好的方法是辅以语义分析(语言理解),关于这个问题,作者将另文讨论。
4. 新型输入法
用户到底对那种输入法感兴趣呢?新浪网对此进行过网上调查(http://tech.sina.com.cn/introduction/focus/input.shtml),虽然参加的人数不算特别的多,在作者定稿时只有三万多人,而且输入法列举得也不全,但基本上可以说明问题。
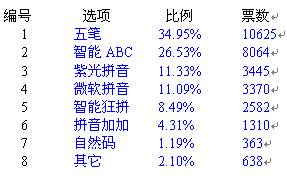
就单项而言,五笔输入法仍然占据鳌头。但是可以看出总体而言,用户更加亲睐基于拼音的输入法,共计占了61.75%,对于PC用户而言这个比例可能还会上升。
北京得意音通技术有限责任公司采用一种新的结构设计,这个结构的底层是精确而小巧的中文语言模型;中层是一棵词法树,以树状结构给出词与字母(构成拼音的最小单位)和笔画(5个国家规范笔画)之间的关系;上层用户界面逻辑层,给出PC键盘、数字键盘、软键盘或触摸屏等与拼音或笔画之间的关系。这种共享结构既保证了各种不同输入手段之间的共享性(不额外浪费资源),又保证了跨平台的可移植性。显然,该结构可以为基于拼音、笔画、数字等的输入法所共享,并可以在PC平台、PDA平台和手机平台上使用。在词基础上,得意输入法支持基于笔画的得意笔输入法和基于拼音的得意拼音输入法,它们都是整句输入法。
得意输入法有如下的特点:
1. 共用一个相同的汉语语言模型内核,嵌入式设备版本的程序大小不到1MB。
2. 笔画、笔顺和拼音完全符合国家标准,用户无需任何专门的学习和记忆。对于笔画,不管某个汉字多么复杂、有多少画,最多就需要输入笔顺的前四个笔画。
3. 支持整句输入方式,输入过程中无需逐字进行候选字挑选。整句输入方式并非只能输入句子,事实上字、词、词组、句子均可,得意输入法本身已经实现了字、词、词组和句子的自动分类。
4. 支持词联想输入方式,输入过程中如果选定某个字,将自动通过联想方式给出下一个可能的汉字供使用者挑选。
5. 既按句子提供整句候选列表(有些句子在首选中没有出现却可能在第二、第三或其他候选中出现),也按字提供候选列表。
6. 整句输入方式和词联想输入方式可以完全自由地切换,无需设置选项,无需按动触发键。
得意输入法是一种无需特殊汉字编码、拆字等的中文整句输入法,它充分利用了中文信息处理技术,为用户提供了精确、快速、方便、人性的输入方法。我们有理由相信,未来人们会更加喜欢使用这样的输入法,在PC、PDA、手机以及各种各样的电子设备上轻松自如地输入中文,随时随地实现信息沟通。
得意音通公司供稿 CTI论坛编辑