常 见 问 题 及 解
答
2004/06/16
得意公司专注于三大核心技术方面的研发:自动语音识别(ASR)技术、声纹识别(VPR)技术,以及中文自然语言理解(CNLU)技术。在此基础上,主要的应用方向包括如下六个方面:关键词检出、语音命令识别、声纹辨认和声纹确认、口语对话系统、嵌入设备上的中文整句输入法、语言学习等。
得意公司核心技术相关的产品和成功案例有:得意接线员、声纹认证加密锁、智能短信信息服务系统、公安领域声纹身份辨别系统等、手机和掌上电脑的汉语整句输入法等等。
得意公司专注于语音、语言、语义等方面的核心技术研发,对其拥有完全自主的知识产权,可为客户提供全面、持久、灵活、多层次的定制化开发和技术服务;得意公司各项核心软件产品的综合性能优越,并可提供完善、方便、易用的编程接口以便搭建各种大中小型应用;得意公司坚持走标准化和国际化的道路,与国内外相关领域的众多企事业单位和学术科研机构等建立了密切的联系,是若干中文相关的标准工作组和联盟的成员。公司拥有一支年轻化和专业化的高水平研发团队,充满了朝气和活力。
通常来说,我们提供的是主要核心软件,包括识别引擎的运行时库、编程接口,以及软件开发工具等。如果需要的话,得意公司也可在现有核心软件或算法的基础上进行定制化开发,搭建具体的应用系统或开发出特定的终端用户产品。
我们的识别引擎是硬件/设备无关的,它只需要拿到用户语音的数据流即可进行识别,并不关心这个数据流是如何获得的。一般可由系统开发商通过语音卡(例如Dialogic、东进等品牌的数字式或模拟语音卡)从交换机上(例如AVAYA、华为交换机等)采集到外线用户的语音流送入我们的识别引擎(当然事先还需通过程序设定待识别的词汇表等参数)即可。具体的设备选型可由开发商或最终用户来决定。
对于语音识别和声纹识别引擎来说,主要以动态链接库(*.dll)的形式提供和调用,由.h文件提供函数原型说明,由.lib文件提供对该dll的函数入口连接。适用于Win32环境,例如Windows 9X/ME/2K/XP等。其外在编程接口是以纯C的函数形式提供的,可供包括MSVC++在内的多种编程语言和开发工具的调用。其内核是用标准C++和相应的模板库编写,不涉及到MFC类库,因此具有很好的可移植性。如果需要的话,只需进行少许修改并重新编译,即可适用于Unix/Linux等其它平台。它们还各有一个适用于Pocket PC的版本。
对于得意中文整句输入法软件来说,主要用于嵌入式设备,它们所支持的平台包括Pocket PC、Symbian(例如Nokia 9210c/6600)、Palm等。
对于得意的各项识别引擎,目前在自动语音总机(得意接线员)等方面的应用一般采用高档PC或服务器,通常最低配置是P4 1.8G CPU,256M内存,100M硬盘可用空间。当然要运行更大规模的IVR(Interactive Voice Response),配置是越高越好。
ASR是自动语音识别(Automatic Speech Recognition)的缩写,其目标是让计算机能够辨别出人们所说的话的内容。ASR通常有以下几种分类方法:(1) 特定人和非特定人;(2) 小词汇量、中词汇量和大词汇量;(3) 语音命令(孤立词)识别、关键词检出,以及连续语音识别(听写)等。
其中语音命令识别引擎要求用户所说的语音中最多只能含有一个词表中定义的词;而关键词检出引擎中则允许用户所说的语音中除了含有一个或多个词之外,还可以包含其它无关的内容,识别器将只检测出那些在词表中定义过的词,同时忽略其它无关的内容;连续语音识别引擎则会把用户所说的语音逐字逐句地转换为文字,是实现“声音”到“文字”转换的技术,它的实现中涉及到声学模型和语言模型:声学模型用以从声音信号中识别出“音(例如拼音)”,而语言模型用以把“音”转换成“字(例如有意义的文本语句)”。
ASR与TTS(Text-To-Speech,也称为“语音合成”或“文语转换”)都属于语音技术的范畴,但他们是完全相反的两个过程。ASR是从语音到内容的识别过程,而TTS是从文字到声音的转换(即由计算机把给定的一段文本转换为语音念出来)。目前得意公司的研发范围不包括TTS。
“得意语音命令”采用的种孤立词的自动语音识别技术,用于语音命令和控制。它要求使用者只能说使用者或设计者预先定义好的词,不能夹杂其他的词或音。适用于任何家用电器和电子设备,比如电视、计算机、汽车、音响、冷气等的声控遥控器,电话、手机或PDA上的声控人名拨号、数字录音机的声控语音检索标签、儿童玩具的声控等,也可用于个人、呼叫中心,以及电信级应用的信息查询与服务等领域。
“得意特定人语音命令”识别引擎及其API的最新版本为2.0。
系统要求为:Intel PII 400 MHz以上配置的 PC或服务器;128 MB 或更多的内存;微软Windows 9X/ME/NT/2000/XP;微软Visual C++ Version 6.0 或更高版本。或者是:ARM兼容的Pocket PC(WinCE 3.0或更高版本);Embedded Visual C++ v3.0或更高版本(适用于Pocket PC版的特定人语音命令识别引擎)。
软件开发包的内容有:函数说明头文件(*.h)、静态链接库(*.lib)、动态链接库(*.dll)、初始模型文件、编程参考手册(*.doc/*.PDF)、参考示例源程序等。
得意特定人语音命令识别API v2.0的特点有:工作在特定人、孤立命令的识别方式;对训练次数要求低,并可累积训练;对用户无口音和语言的使用限制;运行于开集方式(即具备拒识功能);可调整的拒识严格程度阈值;内嵌对并发操作的控制,支持多线程调用;具有高效率与高准确度下的可靠性与灵活性。
“得意非特定人语音命令”识别引擎及其API的最新版本为3.0。
系统要求为:Intel PIII 800MHz以上配置的 PC或服务器;256 MB 或更多的内存;微软Windows 9X/ME/NT/2000/XP;微软Visual C++ Version 6.0 或更高版本。
软件开发包的内容有:函数说明头文件(*.h)、静态链接库(*.lib)、动态链接库(*.dll)、声学模型等运行时数据文件、编程参考手册(*.doc/*.PDF)、参考示例源程序等。适用于Pocket PC版的非特定人语音命令识别引擎将于近期推出。
得意非特定人语音命令识别API v3.0的特点有:非特定人、连续语音;孤立词词表可以更改;目前支持标准普通话;阈值 (或称操作点) 可以调整;高效、精确、灵活、可靠;以及基于客户端/服务器模式的框架结构 (多线程+多事件)。
“得意关键词检出”技术是一种自动语音识别(ASR)技术。它应用于一些具有特定要求的场合:由于速度、高检出率或其他特定的要求,人们并不需要系统识别出整个句子,更不需要理解整个句子,而只关注那些包含特定词(称为“关键词”)的句子,或是关心所说的句子中是否包含了所关心的关键词。比如,对一些特殊人名、地名和词语进行电话监听,又比如通过人名进行自动分机接驳服务,等等。
“得意关键词检出器”及其API的最新版本为2.1。
系统要求为:Intel PIII 800MHz以上配置的 PC或服务器;256 MB 或更多的内存;微软Windows 9X/ME/NT/2000/XP;微软Visual C++ Version 6.0 或更高版本。
软件开发包的内容有:函数说明头文件(*.h)、静态链接库(*.lib)、动态链接库(*.dll)、声学模型等运行时数据文件、编程参考手册(*.doc/*.PDF)、参考示例源程序等。
得意关键词检出器API v2.1的特点有:非特定人、连续语音;关键词词表可以任意定制而无须重新训练;目前支持标准普通话;可方便地调整阈值(或称操作点)以适用于不同的应用需求;每句话允许检出的最多关键词数量可以预先设置;良好的拒识性能和检出率;以及基于客户端/服务器模式的框架结构 (多线程+多事件)。
得意公司的各项ASR识别引擎均支持PC声卡信道和电话信道,它们的采样率分别为16kHz和8kHz,其它采样率的语音流需要先进行转换之后才能被使用,采样点可以是8bit或16bit的PCM格式,也可以是用A率或μ率压缩的。
如果语音流是存储在语音文件(例如*.wav)中的,那么应用程序在调用识别引擎的API之前,需要先将文件中的语音流读入内存中,然后调用相应的编程接口把语音数据送入识别引擎。
我们的识别引擎是支持并发识别的,在一台高档PC或服务器上可以支持几十路语音的同时识别(峰值),再考虑到语音门户流程中的采集语音、播放提示音、等待用户反馈等较低负载的操作,一般每台计算机能够同时服务的线数可在此路数上再乘以某个倍数(例如5倍)。但当更多的用户同时接入系统时,肯定是需要线性增加服务器的数目,由多台计算机同时运行以分担负载。需增加服务器的具体数目需根据该应用的性质、中继数目,以及它对语音识别引擎调用的密集程度等来估算。
一种作法是每台计算机分别独立地服务于一组固定的中继线;另一种作法是,我们可以为此定制该识别引擎的编程接口,并编写通信程序,使得这些计算机上运行的各个识别引擎之间可以协同分配识别任务,均衡负载。
在IVR项目中,得意目前提供SDK的形式。我们有相关的调用例程源码可供参考;因此从应用层对该SDK的接口调用来说,不存在什么技术难点。
VPR是声纹识别(Voiceprint Recognition)的缩写,有时也称为说话人识别(Speaker Recognition)。每个人的指纹都是唯一的,数百万人之间才会发现有两个人有相同的指纹;与此类似,声纹也是人的个性特征,很难找到两个声纹完全一样的人。声纹识别,就是要根据人的发音特征,识别出某段语音是谁说的。
从对用户所说内容的要求上来看,可以分为文本相关的(Text Dependent)和文本无关的(Text Independent),前者要求用户在识别过程中说出和用来训练的语音相同内容的一段话,后者则无此限制;从识别的目的来看,可分为声纹辨认(Voiceprint Identification)和声纹确认(Voiceprint Verification),前者要判断出某段语音是若干人中的哪一个所说的;后者则确认某段语音是否是指定的某个人所说的;在声纹辨认应用中对集外说话人的处理方式上,又可分为闭集识别和开集识别,前者要求待识别语音一定是某个已知的说话人之一,而后者允许待识别语音可以是某个未知的说话人,因此识别系统具有一定的“拒识”的功能,显然后者具有更广的应用范围。
得意公司的声纹识别引擎包括声纹辨认和声纹确认版本,可以是文本无关的,也可以是文本相关的,而且均支持开集的识别方式。其中文本无关的版本同时具有文本和语言的无关性,对语音长度的要求也非常低,通常训练只需要几十秒有效语音,而识别阶段只需几秒钟的有效语音即可。有很高的识别精度,也可以灵活地调整操作点参数从而适应于不同应用的需求。
“得意文本相关的声纹确认”识别引擎及其API的最新版本为3.0。
系统要求为:Intel PII 400 MHz以上配置的 PC或服务器;128 MB 或更多的内存;微软Windows 9X/ME/NT/2000/XP;微软Visual C++ Version 6.0 或更高版本。或者是:ARM兼容的Pocket PC(WinCE 3.0或更高版本);Embedded Visual C++ v3.0或更高版本(适用于Pocket PC版的文本相关声纹确认识别引擎)。
软件开发包的内容有:函数说明头文件(*.h)、静态链接库(*.lib)、动态链接库(*.dll)、初始模型文件、编程参考手册(*.doc/*.PDF)、参考示例源程序等。
文本相关的声纹确认识别API v3.0的特点有:工作在说话人(声纹)文本相关的方式;对训练次数要求低,并可累积训练;对用户无口音和语言的使用限制;运行于开集方式(即具备拒识功能);可调整的拒识严格程度阈值;内嵌对并发操作的控制,支持多线程调用;具有高效率与高准确度下的可靠性与灵活性。
“得意文本无关的声纹辨认”和“得意文本无关的声纹确认”识别引擎及其API的最新版本均为3.0。
系统要求为:Intel PII 400 MHz以上配置的 PC或服务器;128 MB 或更多的内存;微软Windows 9X/ME/NT/2000/XP;微软Visual C++ Version 6.0 或更高版本。
软件开发包的内容有:函数说明头文件(*.h)、静态链接库(*.lib)、动态链接库(*.dll)、初始模型文件、编程参考手册(*.doc/*.PDF)、参考示例源程序等。
文本无关的声纹辨认和声纹确认识别API v3.0的特点有:同时支持话者身份识别与话者身份认证;与文本(内容)、语言无关;运行于开集方式(即具备拒识功能);可调整的声纹识别阈值与自适应适应性功能;无监督的开集拒识阈值估计;话者识别与认证的增量方式识别;高效率与高准确度下的可靠性与灵活性;基于客户端/服务器的框架(多线程与多实例)。
声纹辨认:刑侦破案、罪犯跟踪、国防监听、个性化应用等等;声纹确认:证券交易、银行交易、公安取证、个人电脑声控锁、汽车声控锁、身份证、信用卡的认证等。
得意的声纹辨认和声纹确认技术均提供一组方便易用的编程接口(API)和运行文件,可供应用开发者直接编程调用。其中API部分采用标准的纯C风格,提供函数说明的头文件,可供多种编程语言和环境调用,运行文件包括动态链接库和预先训练好的初始数据文件等。对具体应用对应的特殊信道,我们可以为其进行特定的参数调整和信道初始模型的定制化工作。
与ASR引擎相同,得意的各个声纹识别引擎均支持PC声卡信道和电话信道上采集的语音,它们的采样率分别为16kHz和8kHz,其它采样率的语音流需要先进行转换之后才能被使用,采样点可以是8bit或16bit的PCM格式,也可以是用A率或μ率压缩的。
如果语音流是存储在语音文件(例如*.wav)中的,那么应用程序在调用识别引擎的API之前,需要先将文件中的语音流读入内存中,然后调用相应的编程接口把语音数据送入识别引擎。
在我们现有的声纹识别接口中,已包含了对语音进行预处理的功能。例如识别前,要求先将语音数据放入某个内部数据结构内,在这个过程中就自动完成了抛除静音、噪音、提取语音特征等工作,并为后续的识别只保留真正“有效”的语音部分。当然如果需要的话,系统开发者在这个过程之前再加上一些额外的预处理也是可以的,例如可对某些已知具有特殊分布规律的低信噪比语音进行专门的去噪操作,以保证后续的建模和识别过程具有更好的综合性能。
在进行声纹辨认时,由于进行比对的时间与语音长度和声纹数据库的规模基本上是成正比的,所以当语音较长且声纹数据库巨大时,单一线程内部的比对会变得非常耗时。此时可以采用多台机器协调工作的方式。例如,采用五台机器,由总控程序将一个待比对的语音数据流分发到各个机器上,每台机器只负责比对数据库中五分之一的声纹模型;之后将各自检出的候选提交给总控程序,进行统一的排序和输出,于是总体的识别时间就降为原来单机的五分之一。这就是多机协调工作的方式。
在进行文本无关的、开集的声纹辨认和确认时,我们利用了一种由海量数据训练得到的“通用背景模型”来对各个声纹模型的得分进行归一化和拒识;对不同的信道(例如PC声卡、固定电话、GSM或CDMA的移动电话、录音笔、磁带、监控设备、电视、无线电设备等,严格说来都分别属于不同信道),不同信道的“背景模型”间的参数差异很大,这与识别器的性能是有一定的相关性的。目前我们的引擎中缺省仅内嵌了一个背景模型。因此当需要同时识别来自多个信道(例如手机、固话、录音笔、磁带等)的语音时,我们可训练出针对不同信道的背景模型,在识别时与这些语音对应起来使用即可。当然,现有的编程接口也可以根据用户的具体情况为此进行一些定制或调整。
CNLU是中文自然语言理解(Chinese Natural Language Understanding)的缩写。ASR技术让计算机能“听写”出人类的所说的内容,而NLU技术则让计算机能够“理解”人类的语言并产生相应的处理。
得意公司开发了在中文语言理解方面国际上第一个集成的、可视化的、面向领域开发的口语对话系统SDK,利用该开发工具,可以大大缩短开发周期。我们的系统支持多话题、话题可转移、上下文相关分析(包括省略分析)、人机混合主导等。我们的系统支持的是灵活随意的口语对话,并能根据对语义的真正理解,采用先进的自然语言生成技术,产生自然的应答语句。一个口语对话系统包括的主要部分有:语义分析器、对话管理器、应答生成器等。我们在这几个方面都做得很好。系统的维护比较方便,一般通过修改配置文件就可以达到对系统进行升级的目的。
4.3.1 什么是得意口语对话系统软件开发包(d-Ear SDS SDK)?
口语对话系统(Spoken Dialogue System, SDS)在人机交互的诸多相关领域中非常有用。但是开发一个口语对话系统非常困难,需要具备许多有关计算语言学的知识,具备整个系统的有关知识和开发技巧,设计和实现具体的对话管理器及所应用的对话策略。
得意口语对话系统软件开发包(d-Ear SDS SDK)是得意公司完全自主产权用于开发该类系统的工具包,是目前世界上唯一的实用汉语口语对话系统开发包。
利用d-Ear SDS SDK可快速并有效地开发出实用的得意口语对话系统。对于一个中型规模的系统,1个月左右即可上线应用,系统应答正确率可达80%以上;经过两至三月的实际运行和改进(例如根据实测情况适当增加一些关键词汇和语义解释规则),系统应答正确率可迅速提高到98%以上。
4.3.2 目前最新的得意口语对话系统软件开发包版本是多少?
2003年2月28日,得意公司开发了d-Ear SDS SDK的最初版本。该版本提供了可定制的得意语义分析器(d-Ear Parser)和得意对话管理器(d-Ear DM),提供了支持多路对话同时进行的口语对话系统构架,提供了实现语义分析函数框架的工具SemanWiz。
经过几次版本更新,2004年4月,得意公司将d-Ear SDS SDK升级为2.0版本。该版本
4.3.3 得意口语对话系统软件开发包V2.0的组成如何?
d-Ear SDS SDK V2.0包括以下几个部分:
4.3.4 得意口语对话系统软件开发包V2.0的系统要求是什么?
利用得意口语对话系统,用户可以口语化的自然语言通过网页、手机短信、电话等多种形式,获取后台知识库中的相关信息。以前无法开展,或者用户难以使用的智能互动查询服务都能快捷、简单地开通,为用户提供前所未有的、自然的、互动的信息服务,如旅游交通、吃喝玩乐、金融证券、交友网聚、智力竞猜、公共服务等等各个具体领域的服务。
得意口语对话系统是由得意语义分析器(d-Ear Parser)、得意对话管理器(d-Ear DM)和得意口语对话系统框架(d-Ear SDS Framework)构成的。其中:
得意语义分析器是一个强大的汉语口语分析器,它使用基于语义类的上下文无关增强文法――得意文法(d-Ear Grammar)来描述汉语口语语言。该文法以关键词语义类为终结符;引入了用于汉语口语分析的多种规则类型;将规则按优先级分组,并为每组规则设置词法分析属性;为每一规则关联一种语义解释方法。
得意语义分析器的输入可以是汉语文本句子,也可以是汉语语音识别结果(词网格),输出是用语义框架形式表示的句子语义。
得意语义分析器。可根据实际对话系统相关的领域进行定制。只要定义分析器所需的关键词和关键词语义类,定义得意文法,实现语义解释方法,即可利用得意口语对话系统API,构建和设定用于特定领域的得意语义分析器。
由于汉语口语的特点及口语语音的特点,利用传统文法(转换生成文法)对语句进行分析和理解比较困难。针对传统文法在应用时的缺点以及为了定义规则的方便,得意文法对传统文法进行了扩展,共包括五类规则,见下表。
得意文法规则的五种类型和意义
|
规则类型(符号) |
意义描述 |
|
苛刻型规则(*) |
与传统文法规则相同。 |
|
跳跃型规则(空)
|
规则右端相邻项之间可以存在一些垃圾词。垃圾词的长度可以设定。 |
|
无序型规则(@) |
规则右端各项的出现顺序任意(但右端没有重复项),且各项之间可以存在垃圾词。垃圾词的允许长度与跳跃型规则相同。可认为无序型规则是一组跳跃型规则的组合。 |
|
长程型规则(~) |
规则右端相邻项之间可以存在任意长度的词语(包括垃圾词)。 |
|
交叉型规则(#) |
规则右端各项的出现顺序任意(但右端没有重复项),并且只要不是由原句中同一位置的词归结而来,这些项就可以相互重叠(对于原句中词的位置来说)。显然,交叉型规则的右项中至少有一项是某个长程型规则的左项。 |
为了提高实际应用中对语句的分析速度,并在一定程度上解决歧义,得意文法对规则进行了分类。
首先是规则优先级的分类,即将规则分为不同的优先级组,最高优先级为0,最低优先级为9,默认优先级为5。分析句子时,总是先应用较高优先级的规则,然后应用较低优先级的规则;对于同一优先级的规则,交叉型规则总是在应用其它规则分析完之后才被用来分析,所以实际上得意文法的规则一共被分成了20个优先级层次。
其次是为不同的优先级设定词法分析或非词法分析的属性。在应用某一优先级规则的分析过程中,有一些成分最后归结为当前优先级中最高极的成分,另一些成分只归结为当前优先级的中间成分。如果当前优先级是词法分析的,则只有那些归结得到的最高级成分才会进入下一阶段的分析,那些中间成分会被舍弃,好像没有经过分析归结一样;如果当前优先级是非词法分析的,则所有归结得到的成分都会进入下一阶段的分析。那些进入下一阶段分析的成分的子成分,不再参与以后的分析,――这就是词法分析或非词法分析属性的意义。
得意语义分析器实现真正的语义理解,而不是简单汉字匹配这种表面的语义理解。
得意语义分析器的功能是分两步进行的,第一步对文本句子或语音识别的结果进行文法分析,第二步是对文法分析结果进行语义解释。语义解释的过程就是根据文法分析得到的树状结构,逐层调用每一规则相应的语义解释方法,直至最后文法终结符(即关键词语义类)的语义解释。
得意语义分析器按照一定的算法来确定每一规则所对应的语义解释方法。可以用得意口语对话系统开发环境(d-Ear SDS Studio)中生成语义函数的工具,生成语义解释的框架,使得得意语义分析器能自动识别并正确调用每一规则的语义解释方法。
语义解释的结果是将用户语句所包含的语义用框架方法来表示,相应的框架称为语义框架,框架所包含的槽称为语义槽。在语义框架中已预先定义了对话本身相关的命令、寒暄、无法理解等内容;在语义槽中也预先定义了陈述、疑问、确认、操作等不同的类型。
对话管理器(Dialogue Manager,DM)是口语对话系统中非常重要的一个组成部分,一般处于系统的核心位置。得意对话管理器是具有强大功能的对话管理器,它采用混合主导方式,在复杂的多主题的领域对话中能较好地完成知识管理、交互历史管理和应答推理的任务。
得意对话管理器用主题森林来表示领域概念。了解得意对话管理如何基于主题森林结构进行应答推理,有助于认识得意对话管理器的强大功能,有助于更好地利用得意口语对话系统API来设计和实现特定领域的对话系统。
下面是一个实际的对话例子,对话S方就是使用得意对话管理器的一个提供航班信息查询和订票的系统(U表示用户语句,S表示系统语句)。
|
S1: |
您好,欢迎使用本航班查询订票系统! |
|
U1: |
我要两张去乌鲁木齐的机票。 |
|
S2: |
从北京到乌鲁木齐。您想问哪一天的? |
|
U2: |
后天有吗? |
|
S3: |
后天。有,查到4次不同的航班。 |
|
U3: |
都是什么时间的? |
|
S4: |
起飞时刻为11:25、13:50、19:15和19:25。 |
|
U4: |
什么时候到? |
|
S5: |
到达时刻为15:20、17:40、22:55和23:05。 |
|
U5: |
那我要下午到的。 |
|
S6: |
您要9月20日11:25从北京出发,15:20到达乌鲁木齐的CJ6901次航班的机票吗? |
|
U6: |
好的。 |
|
S7: |
您要2张票是吗? |
|
U7: |
票价是多少? |
|
S8: |
从北京到乌鲁木齐的机票每张2140元。 |
|
U8: |
嗯,我要2张票。 |
|
S9: |
请问您的身份证号码是多少? |
|
U9: |
123456789012345678。 |
|
S10: |
您的身份证号码是123456789012345678吗? |
|
U10: |
没错。 |
|
S11: |
您订了2张票,该记录已加入数据库。 |
|
U11: |
谢谢,再见! |
|
S12: |
谢谢使用本系统,再见! |
在对话系统中,知识包括两部分,一部分是说话人自己所拥有的常识和信息,另一部分是通过对话双方交流得到一些共识(交互知识)。交互历史指对话过程中每一回合的内容,而且在实际人和人的对话中,一般只记忆对话语义,而不是对话时采用的词和句子结构。应答推理指根据对话知识和交互历史,决定当前回合应回答的内容,但不包括使用什么句型或使用什么词汇来得到具体的应答文本。
以航班查询为例,关于航班的常识信息(如航班信息的组成、城市信息、时间概念等等)、航班时刻表、以及查询过程中了解到要查询航班的起终点城市、日期、机型等都是知识。当然,对话双方的知识除了常识和交互知识外,一般都是不对等的,这是通过对话进行信息交互的根本原因。在查询航班的对话中,哪个回合给出起点城市信息,哪个回合给出起飞日期信息,或者哪个回合提问票价,这些都属于交互历史。交互知识可以看作交互历史在语义方面的综合。
知识管理、交互历史管理和应答推理是对话管理器应具备的主要功能,这三方面的性能直接影响到对话系统的理解能力、对话能力,以及智能水平。
主题森林(Topic Forest, TF)是一种知识表示方法,得意对话管理器用主题森林来表示对话任务涉及的领域概念和图式。主题森林由若干棵主题树组成,这些组成信息记录在主题森林文件中。
主题树(Topic Tree, TT)是表示对话单个主题相关的概念和图式的树形结构,包括构成该主题的各项信息及信息项之间的关系,可用来表示对话过程中该主题的交互知识,记录该主题相关的交互历史。主题树由主题结点、中间结点和叶子结点组成。
在得意口语对话系统运行时,得意对话管理器从主题森林文件中读入信息,在内存中建立主题森林,然后以此为基础进行对话管理。
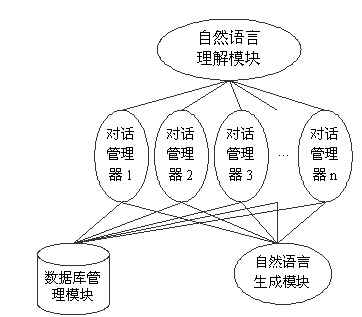
得意口语对话系统框架是一个可同时处理多路对话的系统框架,如下图所示:
从图中可以看到,得意口语对话系统框架只包含一个自然语言理解模块、一个数据库管理模块、一个自然语言生成模块,以及多个对话管理器。在系统运行时,每一路对话都由一个对话管理器负责对话控制,但这些对话可以共享自然语言理解模块、数据库管理模块和自然语言生成模块。
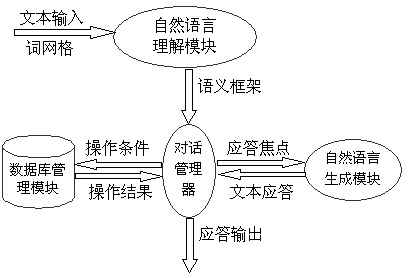
在对话进行时,得意口语对话系统框架各组成模块间数据哦流的输入输出如下图所示:
得意口语对话系统API是一些API函数,在为实际的领域任务定制得意口语对话系统时,通过调用API使得定制的分析器和对话管理器应用于对话系统框架,同时API函数提供了在对话过程中记录和获得对话信息的功能。
得意口语对话系统API可分为四大类:
利用得意口语对话系统框架和得意口语对话系统API,为特定领域的任务建立汉语口语对话系统可采取如下步骤:
领域数据库是对话系统的信息源。得意口语对话系统框架对数据库的组织方式没有特殊要求,可以用任何数据库管理软件来建立和维护领域数据库。为了能被得意对话管理器调用,应实现得意口语对话系统框架中预定义的函数调用接口。
4.3.18 领域特定信息的操作如何在得意口语对话系统中配置?
一些领域特定信息是通过关键词文件、文法文件和主题森林文件和语义解释来表示的,其余信息和操作则用C++程序来表示,为此得意口语对话系统框架定义了一个C++类CCustom。
CCustom类中预定义的需定制化的内容包括:生成任务相关应答、实现领域特殊的语义操作、管理领域特殊的回合信息,以及领域对话本身的特殊操作。
建立多路对话的系统应按以下步骤:
一般来说,得意语义分析器和得意对话管理器的处理时间非常短,即使在多路对话的条件下,也能达到实时要求。但是如果数据库操作所需时间比较长,那么得意对话管理器会等待数据库操作结果,因此在必要时应将步骤6中调用回合应答函数的操作放在一个线程中进行,从而使得多路对话能够并发处理。
TBA.
TBA.
TBA.
得意音通公司供稿 CTI论坛编辑