电子语音玩具设计中语音、软件、功耗等技术的综合考虑
赵大有 2002/10/28
玩具设计看似简单,但是其背后真实的技术背景并不简单,要综合考虑软件和硬件方面的技术设计以及语音处理技术,同时还要选择合适的微控制器及相关外围器件,从而实现低成本和低功耗设计。 今天孩子们的玩具实际上属于一种嵌入式系统,本文跳过玩具产品设计项目中的"概念设计"阶段,直接从项目的工程设计开始讨论,并且假定项目的设计规格说明书(设计指标)已经完成。这些设计规格说明书通常是以游戏模式流程图的方式来详细地描述玩具的行为。我们设想的洋娃娃游戏模式如下:
常规模式:
A. 玩具是婴儿洋娃娃,其腰部配备一个常态为断开的开关(该开关用来检测拥抱洋娃娃的动作),还有一个重力开关(该开关用来检测洋娃娃是站立还是躺下姿势)。
B. 洋娃娃站立时重力开关断开。 C. 洋娃娃站立时,如果腰部开关被按下,洋娃娃将播放下列声音中的一种:哈哈地笑、长时间地大笑、或者以愉快的声调说话。每一次按下洋娃娃的腰部开关,洋娃娃都将循环地播放上述声音中的一种。
D. 洋娃娃躺下时,如果腰部开关被按下,那么洋娃娃会发出哭声,然后转为无声。E. 如果将洋娃娃的姿势由躺下转为站立,洋娃娃就会打哈欠。 F.
如果将洋娃娃的姿势由站立转为躺下,洋娃娃就会发出简短的鼾声,然后转为无声。
语音控制模式:
A. 洋娃娃站立时,如果超过2分钟没有外界信息输入,他会说:"好寂寞呀,怎么没人陪我玩"B.在这个时候,如果还没有信息输入,洋娃娃将播放下列声音中的一种:哈哈地笑、长时间地大笑、或者以愉快的声调说话。C.
洋娃娃站立时,你可以和他进行对话,如"你多大了?"、"你叫什么?"甚至可以和你对诗。D.如果给洋娃娃加上机械动作,我们同样可以用语音来控制它的动作,比如你可以叫他跳舞、唱歌、行走等。
声音处理
工程设计的第一步是记录声音并且将声音信息传送给芯片开发系统。尽管以后还要进行下采样(downsapling),但是对声音信号进行高质量的采样仍然十分重要。从声学意义上讲,该记录过程通常都应该在绝对安静的录音棚环境下进行,要采用44KHz
16位采样方式录制,并直接将声音信号记录在计算机硬盘上。通常情况下应该聘请语音专业人员来从事录制工作,而不是由项目工程师或办公人员来录制。每一个字词或者短语最好录音几次,这样就有选择的余地。
对于那些需要从电子乐器中获取音乐的工程项目来说,更可取的方法是将艺术家的演奏效果记录成MIDI格式。MIDI格式可以修改演奏的乐器以及播放顺序,并且在必要的时候(如根据硬件进一步调整语音性能)去掉多调(polyphonic)成分。
有时,音频工程师还必须通过合并冗余的声音信号来实现被采样声音的分解以压缩ROM空间。一个典型实例就是从1到20之间计数的语音玩具。在这样的玩具设计中,并不需要为每一个数字都单独进行语音采样和录音,语音采样通常从数字1开始到12,然后是数字20,接下来是音节"thir-"(数字13)、"fif-"(数字15)和"eigh-"(数字18),除此之外,还有后缀"-teen"。请注意,"four"、"six"、"seven"和"nine"等语音信号既可以表示这些数字所代表的语音,也可作为音节跟语音后缀"teen"结合表示大于10的数字的语音。
对语音信号进行分解的程度取决于可用存储空间的大小。可以尝试将数字31分解成"thir-"(并且这个音节还可以用于数字13和30)、"-ty"(这个音节可以用于所有带"-ty"的数字中)以及"one"。语音的分解费时费力,要拆分和连接音节,增强爆破音,测试连接音的不同组合以确保连接音的声效像一个连贯字。有时为了得到仅仅几个词的比较理想的声效,可能需要几个星期时间,所以如果没有必要应该尽量避免更进一步的分解。
语音分解的一个极端例子是设计类似于SC-01或SPO256A-AL2这样的音位变体语音合成芯片。芯片中存储了(实际上是合成)一个语音片段库,通过这个语音库你可以组合出各种各样的词。举例来说,你可以从语音片段"d"、"ah"和"g"来构造出"dog"。然而,要保证这种合成的声效听起来非常接近于实际情况就十分困难。
微控制器的选择
在玩具的生产制造中,成本控制是一个重要的考虑因素,所以要尽量选用廉价的控制芯片。这样一来几乎所有带语音的玩具都用4位语音微控制器芯片设计,这些芯片都包括简单的控制器内核、输入和输出管脚、寄存器以及串行访问的ROM,在该ROM中存入一段小程序和大量语音采样信号。
早期芯片采用简单的4位PCM编码技术,能在很短的ROM空间内存储很长的语音编码信号。最新的芯片都采用4位或5位ADPCM技术,这是一种预测编码系统,它利用了模拟信号数字化过程中连续采样之间的相关性。从算法上来说,每一个采样值结合解码器当前的输出状态生成下一个输出状态。利用ADPCM技术,一个5位输入数据流可以驱动一个8位DAC,而且可以产生非常好的声效。尽管这种压缩系统并不产生原始信号的字节流,然而这对于语音和音乐播放来说已经足够了,同8位PCM编码方式相比,可以节省37.5%的ROM空间。
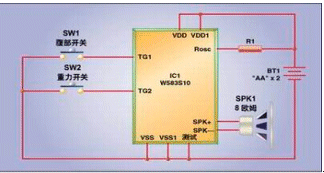
许多玩具采用的外部电路都非常简单,通常包括一个电池、一个用来设定芯片时基的外部电阻、一个小喇叭或一个用于驱动喇叭的晶体管。这些芯片的价格如何呢?一般来说,可以容纳两分钟音频信号的掩膜微控制器裸片,量产条件下成本大约为每片1.20美元。绝大多数的玩具都使用更小的芯片,价格大约在0.15美元到0.30美元。本文讨论的应用选择W583S10,在华邦公司推荐的6.4kHz采样频率下,该芯片仅能存储10秒的语音数据,如图1所示。注意,电阻R1的值取决于采样频率。通常情况下,设计工程师会使用一个电阻替换盒来试验其它阻值。
上述芯片的指令集并不丰富,其指令集通常包括对寄存器加载常量的指令、寄存器增/减指令、设置输出管脚状态指令、无条件跳转指令、寄存器无条件跳转指令以及根据输入管脚状态的条件跳转指令。芯片中实现子程序的唯一方法是在一个寄存器中存储一个返回地址。在对器件编程时,要大量使用GOTO语句,对于一些较大的项目来说,程序中会出现许多冗余代码。
语音识别(控制)系统的选择
语音识别系统的基本流程如图1所示
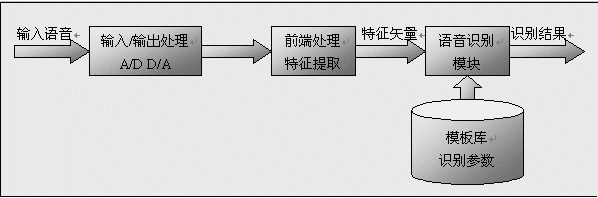
图1 语音识别系统的基本流程
语音信号输入后首先经过滤波器,去除干扰及可能造成混淆的成分,然后由前端处理模块提取语音识别所需的特征参数。当前语音识别所用的特征参数主要有两种类型:线性预测倒谱系数(Linear
Prediction Cepstrum Coefficient, LPCC)和MEL频标倒谱系数(Mel Frequency Cepstrum
Coefficient, MFCC)。
LPCC系数主要是模拟人的发声模型,未考虑人耳的听觉特性。它对元音有较好的描述能力,对辅音描述能力及抗噪性能比较差,而其优点为计算量小,易于实现。
MFCC系数则考虑到了人耳的听觉特性,具有较好的识别性能。但是,由于它需要进行快速傅立叶变换(Fast Fourier Transform
Algorithm, FFT),将语音信号由时域变换到频域上处理,因此其计算量和计算精度要求高,必须在DSP上完成。
在此,我们选择准确率最高、功能最全、价格最适宜的Sensory语音识别芯片(RSC164或RSC364)。
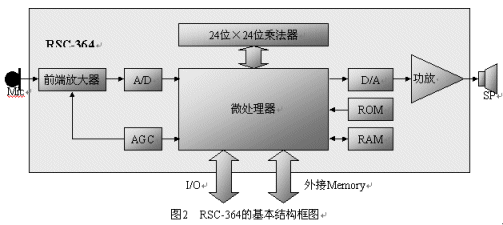
RSC-364
由美国Sensory Integrated Circuit公司开发,2000年开始生产,是一颗为消费类电子产品应用的低价位的语音识别专用芯片,其结构图如图2所示。
RSC-364是一片以8位MCU为核心的CMOS器件,片上还集成了ROM、RAM、A/D、
深圳捷通公司供稿 CTI论坛编辑
| 捷通82语音识别模块产品说明书 2003-06-09 |
| 语音合成芯片情况介绍和产品设想 2003-05-06 |
| 数字可视复读机方案 2003-04-09 |
| 语音识别控制电话机方案 2003-04-04 |
| 智能早教机方案 2003-04-03 |