说话人头像技术: 让语音可视
辛乐 陶建华 2007/07/06
既包括了语音输出,又能够展现说话者面部表情和嘴部、眼部等变化情况的说话人头像(TalkingHead)技术,作为人机交互系统中直接与用户打交道的视觉窗口,能够让用户直接获得“自然”的感觉,受到越来越多研究者的关注。
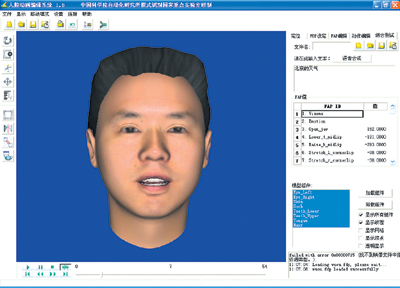
FAP为其中显著特征点的运动
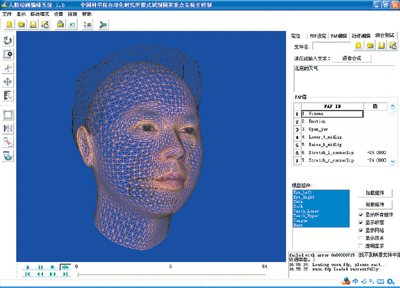
根据正交照片对通用人脸网格模型进行投影计算,得到投影后的人脸网格模型。利用匹配算法对投影后的网格模型进行自动的人脸匹配,所有的特征点都匹配完成后,采用径向基函数算法对匹配结果进行调整。图2是正面侧面人脸图像的匹配结果。为了保证建模结果在静态表现方面的逼真感,我们采用了多尺度纹理映射技术。采用多尺度纹理映射后的结果如图1所示,该图表示从多个角度观察的个性化真实感人脸模型。
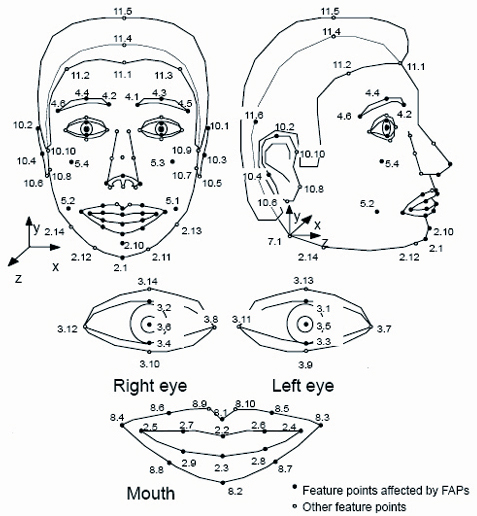
图2 mpeg-4标准人脸特征点FDP示意图
然后根据人脸动画机理,编辑相应的动画规则,合成真实感的人脸动画序列。由于预见到TalkingHead在未来的巨大应用前景,MPEG-4标准引入了人脸动画。MPEG-4标准已经包括了如何生成和编辑人脸动画规则的内容。人脸动画驱动中的关键问题包括了如何定义面部运动参数以及如何根据面部运动参数来变形人脸模型。MPEG-4人脸动画可由三个参数集描述,即人脸定义参数(Facial
Definition Parameters, FDPs)(如图2所示)、人脸内插变换(Facial Interpolation Transform,
FITs)和人脸动画参数(Facial Animation Parameters,FAPs)。FDPs确定模型形状和通用动画规则,FITs定义特定人动画规则,FAPs则可驱动模型生成人脸动画序列。
基于图像数据的说话人头像技术
基于三维人脸模型的说话人头像技术由于其直接性和良好的可控性获得了广泛的关注,但是这种参数控制方法合成的人脸图像质量往往不尽人意,常带有人造的痕迹。近些年越来越多的研究人员尝试直接从图像序列出发进行人脸动画,出现了一些基于图像样本的人脸动画方法。
基于图像的人脸动画的生成过程也就是基于图像的绘制过程,即直接对平面二维图像进行有效的分析,在完成与语音对应的条件下,最终合成人脸动画,同时包括表情同步表达的完整图像序列。这种方法一般分为分析和合成两个阶段。在分析阶段,通过图像处理和语音处理的方法建立一个包括大量图像样本的数据库,同时保存关于这些样本的各种结合参数及语境信息。在合成阶段根据特定的语境信息从样本库中选择核实的样本,通过图像变形技术将它们拼接生成新的可视语音。数据库的大小及合成质量与具体的实现方法有关。
现有的实现方法主要有以下三种:
语音-视觉映射方法
语音-视觉映射是整个语音驱动说话人头像技术中最关键技术之一,包括了语音合成技术和人脸动画技术两个已经获得了很大发展的研究领域。对前者而言,通过利用大规模语料库和波形拼接算法,已经可以合成出较为流畅的语音,并已经获得了很大范围的应用。对于后者,人们利用计算机动画和图象处理技术,运用机器学习方法,也已经可以模仿合成出非特定人的任意表情。但当研究人员期望将语音合成技术和人脸动画技术进行融合,构筑能说会道和富于表情的人脸表达时却遇到了困难。由于语音、唇动和脸部表情之间是多对多的复杂映射关系,所以实现高自然度的人脸表达,不仅仅涉及到语音与人脸的同步映射模型的建立,还涉及到其他内容。如在语音韵律特征下的表情生成以及与个性化特征的融合,以及人们对人脸及其运动太熟悉,对其运动的动态同步特性非常敏感。
构筑个性化真实感强的说话人头像无疑是自然人机交互领域值得深入研究的课题,也受到来自企业界和学术界越来越多的关注。它不仅具有非常广阔的应用背景,而且具有揭示人类交互过程中各种媒介之间相互作用的深刻理论意义。中科院自动化所对相关关键问题作了有益的探索,并取得了不错的成果。但是针对该项研究,仍然需要开展广泛的合作,并在实际应用场景进一步研究,说话人头像技术才会有更加美好的应用前景。
根据语音-视觉之间构建同步映射模型的基础不同,语音-视觉映射可分为两大类: 基于文本的语音-视觉映射和基于语音驱动的语音-视觉映射。基于文本的语音-视觉映射系统的输入是文本信息,在输出合成语音的同时,也需要输出人脸动态图像序列。其语音-视觉映射是基于音素层的,也即整个工作的核心建立人脸视位与特定音素之间的对应。在动画合成过程,输入语音被分解为音素(元音和辅音)后,找到其对应的视位口形,并按照一定的规则抽取和平滑拼接,从而生成语音动画。
而语音驱动的语音-视觉映射技术路线则是在大量数据的基础上,利用统计学习的方法对双模式数据进行分析。同时利用神经网络,线性预测函数等数学工具学习语音信号特征参数与人脸运动控制参数之间的映射关系,完成由新输入语音直接驱动嘴唇运动的目的。众多的机器学习方法被用来表达双模态参数之间的统计关系,比较有代表性的方法包括:
中科院自动化所也针对语音-视觉映射提出了动态基元选取算法(图3)。该算法受到语音合成中基元选取的方法启发而用于语音-唇动映射,选用音频匹配误差和前后基元间的视觉匹配误差在一定的加权系数平衡下的代价函数。区别在于,语音合成是在语音库里选取合适的语音基元,拼接合成一段新的连续的语音;
而语音-唇动映射则是在训练数据库中选取合适的语音-视觉双模态基元,合成一段新的连续的FAP 参数流,用来驱动三维人脸动画。
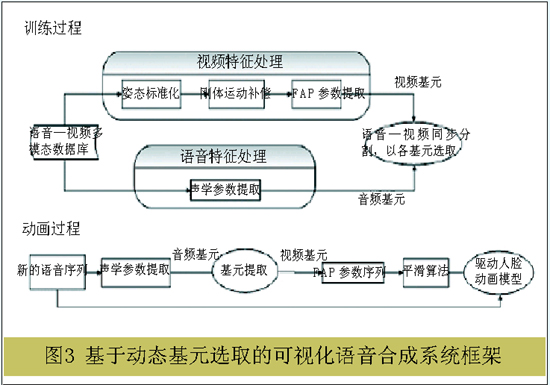
图3 基于动态基元选取的可视化语音合成系统框架
此外,中科院自动所还采用了一种基于Inversed HMM的方法,更为有效地实现了连续动态的人脸动画序列的拼接和生成。为配合此项工作,不少单位还购置了专业的设备,如中科院自动化所采购了运动捕捉设备(如图4所示)。这种成熟常用的光学式运动捕捉方式通过在表演者的脸部表情关键点贴上Marker,然后利用计算机视觉方法来计算得到Marker的运动轨迹。表演者可以比较自由地表演,使用方便,同时marker可以方便地进行扩充或去除。缺点是受外界环境的影响很大,需要比较多的人工干预,后处理的工作量很大。

图4 (a)运动实时捕获设备;(b)人脸标记位置示意;(c)采集样本
| 智能通信终端的关键技术研究 2007-06-19 |
| 自动语音系统:虚拟人物提供人性化呼叫业务 2007-01-23 |
| 刘庆峰 丈量梦想到现实的距离 2006-06-05 |
| 语音技术“入侵”电话服务 颠覆传统通信 2006-03-10 |
| 手机里的语音技术,你了解吗? 2006-02-24 |