语音技术开发与应用
徐 波
计算机已渗透到生活的各个角落,计算机的普及化、家电化、各种类型的计算平台都需要更简便的输入媒体,语音当仁不让成为用户最佳的选择之一。在社会应用驱动下,迅猛发展的语音技术面临着巨大挑战。作者从用户、系统设计者角度阐述语音技术开发应用中要注意的一些问题。
目前,语音识别技术在计算机硬软件的推动下,经过几十年的探索,正进入一个黄金时代。虽然其发展程度与人类的听觉能力相比还处在初期阶段,但其多年技术积累以及固有的交互优势已经使它能广泛地应用于社会各个方面的人机交互中了。本文从用户和系统设计者角度阐述在目前语音技术条件下,对该技术开发和实际应用中的一些认识。
技 术 特 点
要了解语音界面(Speech User Interface)的设计和应用问题,最重要的就要抓住当今语音技术的特点和限制。ASR的基本原理是通过比较用户的发音与计算机中的音素、词或短语的模型、模版来完成的,它只能从现有的模型中找出一个最近的模型或序列来作为识别结果。但由于受生理、心理等条件影响,人的发音在长度、韵律等方面会不断变化,另一个意思的句子可以有成千上万种的表达方法,所以这种匹配不但非常困难,而且不可能是非常精确的,下图表示了一个简化的语音识别原理图:
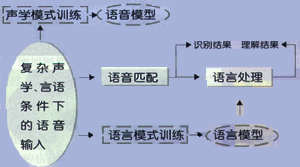
图中所画虚线部分成为训练模块,实线部分为识别模块,一些小词汇量的、孤立语音识别器没有经过语言处理直接输出识别结果,而大词汇量的语音识别则需要经过语言理解。在图中的语音输入端,除了上面提到本身说话人发音变化外,在语音信号进入识别器前,声学上还会受到环境噪声、通道噪声、不同人说话方式、不同口音等影响,现有技术还不能采集到所有这样的样本情况,也没能对所有这些信号进行最有效的概括、处理和存储,识别器对这些因素变化还比较敏感,特别是在词汇量比较大时,这些影响会更加严重。语言的产生过程则经历由概念形成、文本生成到语音输出等过程,由于一个概念具有多种表示方法,而且人类的发音过程在一定程度上与思维过程是一个不断交互的过程,这造成口语现象的高度复杂(例如重复、修正、迟疑、句子没有语法、省略等),所以语言模式训练含有声学模式训练中碰到的同样的样本多样性问题。另外目前的语音识别系统还没有一种很好的对识别结果可信度的恒量机理,这种状况要么造成系统的过多拒识,要么对非系统所需的语音作出错误的响应。
前面我们着重描述了语音识别的机理以及问题来源,结合语音识别技术在近十年的迅速发展,语音技术具有其自身的发展特点,这些特点对理解语音识别技术的开发和应用具有重要意义。这些特点概括起来包括:
1. 语音识别在受限条件下已取得重大进展,在技术上相对比较成熟。例如办公环境下具有说话人自适应能力的专用文本标准语音听写识别,恶劣环境下的专用小词汇量识别,小词汇量非特定人命令识别;小词汇量关键词检测;专用领域的中、小词汇人机对话等等;事实上,对于许多应用来说,并不需要一个系统具有象人类能力一样的高级识别能力,一个系统只要对一组词汇或命令能进行比较一致的区分,它就可能为用户提供一个有效的工具完成任务。这一点决定了现有的ASR技术已经具备这样的能力来完成越来越多的实际应用需求。
2. 除了一些通用环境下的语音识别外,几乎所有的系统需要针对某一个应用进行工程化的设计和实现。对于不同的应用解决问题的着重点不一样,而目前的语音识别还不能在同一框架下去解决所有复杂的问题,因而有针对性地解决问题的方法至关重要。这需要遵循一定的开发模式,这种开发模式从应用的提出、识别策略的指定到真实应用环境下数据的采集和建模到测试使用需要经过多个循环才能达到实用化的程度,特别在电信网络的语音识别应用。
3. 正是由于语音识别技术存在的上述问题,使得语音识别技术还远远不能满足各种用户提出所有要求,即使在技术上可以达到,也需要比较长的时间完成一个除PC外的实际系统装置。这种状况严重影响该技术的推广和在各种领域内的渗透,是目前语音识别面临的重大应用挑战。
用 户 期 望
人类在长期的社会实践和复杂环境中逐步建立起了完善的语言听觉功能。在过去十年里,人们在大词汇量、连续语音(LVCSR)和非特定人的识别上取得了巨大的进展,实验室系统(非实时)对大多数说话人和专用文本的词识别错误率已降低到5%―10%的水平,在一些非常专用的领域内语音识别确实也取得了很大的进展。人类对自身识别能力的直观认知和语音识别的巨大进展两个因素,再加上各类产品广告的误导,用户对语音识别非常容易产生不切实际的期望。由于期望与现实的差距,用户对语音识别技术将是挑剔的。
但是人们对语音技术的接受又将是热情的。在美国通过对一些使用ASR电讯语音服务的客户调查表明,一个总的结论是,用户还是非常愿意与机器对话,只要这种对话能够满足用户的某种需求,尽管现有识别系统有这样那样的缺点,也会受到欢迎,汽车行驶中的声控拨号就是最明显的一个例子。
对语音识别的用户来说,还有一个重要的问题是人机的协调问题,是机器适应人还是人主动地适应机器?无疑技术的不断探索需要以人为本,不断简化人们使用和操作过程。但观察人类交流过程中的语言,我们就会发现与不同知识层次、不同年龄层次等人群进行交流时,会主动地改变、调整自己的语言风格。例如对儿童说话时,我们会尽量采用短的句子、简单的词汇、比较轻缓的语调,使得交流更有效率和容易。研究表明,绝大多数成年人,也会对机器的语音识别表现一种自动的自适应能力,包括说话的音量、语速、说话方式,一般用户总会在一定时间内摸索到系统的脾气,这就涉及到用户对一个新生事物的耐心问题。例如对于听写系统,美国PC
Magazine通过对美国最领先的几个听写系统的测试和比较认为:毫无疑问,用户只要肯花时间训练系统并熟悉整个听写过程,他就可能从听写中获益。但编辑同时写道,用户可能花一个小时的时间就可以装上系统,但可能需要花一个月的时间试用并不断加入自己所需要的词汇、才能真正以最佳状态地使用系统。因而编辑特别认为那些对听写真正需要、并且对这种新技术很有热情的那些人,将更会从中获益。
应 用 设 计
正是由于目前语音识别器的局限性,它还无法处理象人类那样随意的自然语言和任何语音,只是在有限的条件下取得进展,因而针对实际需求可以产生很多的分类。
下表从不同角度列举了语音识别系统的类型:
对于一个需求来说,首先需要确定设计识别系统的类型,这种类型的确定最终需要在了解目前各类识别系统的处理能力的基础上,在用户的说话自然度和系统的开发量、识别率之间得到一个折中。以确定特定人识别系统和非特定人语音识别系统以及词汇集的选择为例。特定人最大的优势是识别率高、通过重新训练可以方便地适应各种不同的声学环境。对于特定人语音识别系统来说,一般系统需要提供一个工具,由系统提示用户发音一组命令、句子等。这种情况下,一方面系统在技术上不但必须保证用户发音同屏幕上的提示的一致性,而且要校验用户不同遍发音之间的一致性,另一方面很难避免由用户定义的发音和词组可能在用户的应用范围内有非常容易混淆的词对。
表1:识别系统的分类
| 分类方式 |
对说话人敏感程度 |
识别词汇量 |
发音方式 |
识别模式 |
|
分类
|
1. 特定人系统
2. 非特定人系统 (男声、女声、童声、成年人声音、老年人等声音种类),
3.说话人自适应系统 ... |
1. 小词汇量
2. 中词汇量
3. 大词汇量 |
1. 孤立发音
2. 连续书面语发音
3. 口语化语音... |
1. 命令识别
2. 关键词检测
3. 语音理解:人机对话
4. 文字记录(听写)
5. 语音翻译 ... |
这些问题在非特定人语音识别中可以避免。但要设计一个非特定人语音识别系统,系统的词汇表是一个重点需要考虑决策的问题。每选择一个新词必须充分考虑这个词对于用户的用途以及该词在声学上同其它词汇的混淆度,在用户容易控制和识别器容易识别这二者之间必须有一个平衡。其数据的采集必须充分考虑用户真正的使用环境。例如不同的麦克风、不同的线噪声、不同的背景噪声,这些建立起的模型必须充分考虑从不同地方语音引起的不同的声学环境和口音特性,但说话人无关系统的完成则是一劳永逸的。
显然非特定人系统需要花费很大的人力和才力完成数据的采集、试验和模型的建立,而许多市场方面则希望在很短的时间内把一个应用建立起来,这方面特定说话人系统又具有很大的优势。另外在PC平台上的大词汇量语音识别,通过少量语音的自适应达到特定人的效果,说话人自适应识别系统最具有优势。
在个人电子消费的大背景下,特定人系统在实际场合中能得到非常广泛的应用,具有得天独厚的优势。利用特定人识别能把录像机复杂的操作过程简单化;又如手机的拨号,在早期的手机中,一般左手拿手机,右手拨号;现在的手机逐渐微型化,但在拨号时,仍然需要把眼睛的注意力集中在上面,采用语音拨号则完全能避免这种情况。又如我们最近研制成功的基于PalmPC的语音识别系统,就充分考虑了该计算平台内存少、计算能力弱、个人专用的特点而设计成为特定人系统,取得了非常好的效果。
从用户心理出发,对系统的响应时间、识别结果的反馈、系统给予用户的提示方式、如何改善人类语音的发音自然度最后提高交互效率,着重需要在具体界面上进行精心设计才能保证达到最佳效果。
未 来 展 望
在社会潜在的应用驱动下,语音识别理论和技术得到飞速发展。但由于语音信号的复杂性和其包含的符号的高度抽象性,它也面临着巨大的挑战,然而人类的探索能力是永无止境的。虽然有人质疑办公室环境下听写系统的实际用途,然而在一般的会议记录、纪实采访和电视广播语音中,把语音整理成文字之类的软件孕育着巨大的市场需求。在未来几十年中,语音技术还将在所有涉及人机界面的地方无处不在,无时不在。特别在电讯服务、信息服务和家用电器中,以“自动呼叫中心”、“电话目录查询”、
股票、气象查询和家电语音控制等为代表的语音应用将方兴未艾。人机对话就会象人人对话一样的平常。而结合语音识别、机器翻译和语音合成技术的直接语音翻译技术,将透过计算机克服不同母语人种之间交流的语言障碍。语音也将成为下一代操作系统和应用程序的用户界面之一。
HAL,这个语音处理能力完全可以与人类相媲美的计算机,决不会有朝一日突然来临,它需要人类在口语信息处理这个领域进行不懈的探索并不断取得实质性进展后才能到达这个光辉的顶点。目前作为语音技术的一个关键转折点,它为解决现实世界中的许多问题提供了解决的能力,那些受传统交互模式困扰的用户也许会从这个技术中获益。然而这样的技术要为真正的用户所接受,则必须在系统的设计阶段充分考虑现有技术的特点、用户的使用习惯和心理,提供出较原有交互模式更为优秀的特点来,才可能取得巨大的成功。
作者简介:

徐波,1988年毕业于浙江大学,1992、1997年在中国科学院自动化研究所获模式识别和智能控制专业硕士、博士学位。现为该所研究员、博士生导师、模式识别国家重点实验室副主任。多年从事语音信号处理、识别和理解方面的研究,目前工作重点在语音翻译技术的研究和语音识别技术的实用化开发上。
摘自《中国计算机报》1999年5月10日
相关链接: