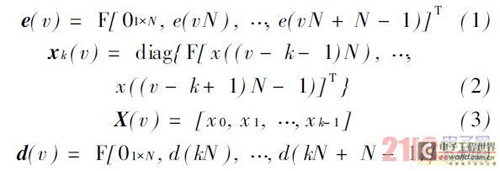
基于DSP的音频实时处理系统
2011/03/14
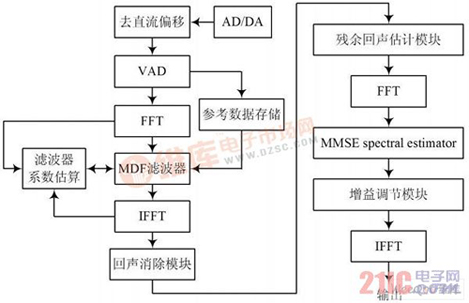
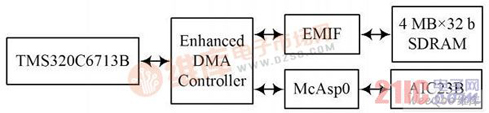
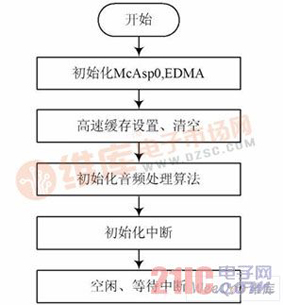
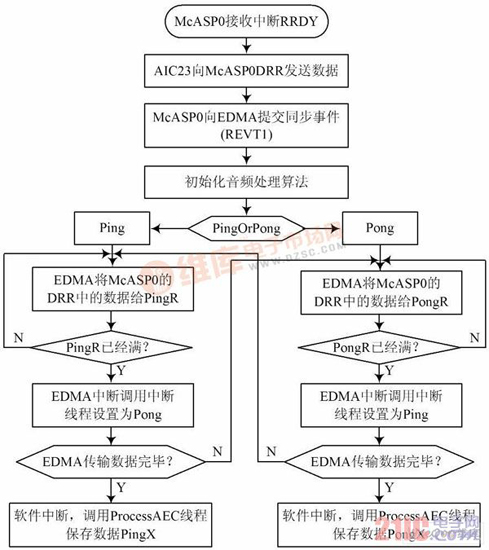
摘 要:声学回声消除器一直是视频会议系统不可缺少的组件。将回声消除算法结合噪音消除和静音检测算法等,提出一种改进的实时音频处理系统方法,并在TMS320C6713B 上实现,能够有效改善噪音、双工检测、非线性回声等导致自适应滤波器发散的问题。该系统在保证正常双工通话的同时,对非线性回声的抑制有着明显的改善效果。
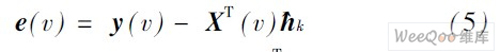
211C电子网
| 白皮书:呼叫中心测试的商业利益 2011-03-09 |
| 一款图形化的IVR开发工具――SCS 2011-03-07 |
| 物联网与电信网融合技术分析 2011-03-04 |
| 面对KIK这类挑战 运营商当以平台应万变 2011-03-04 |
| 智能客服机器人――以人工智能服务电信客户 2011-02-28 |