
新闻中心/NEWS
壹鸽AI技术小贴士-标签挖掘介绍
2020-11-09 10:18:32
随着壹鸽AI技术日趋成熟,最具代表性的智能语音客服机器人已经在快递物流、银行、保险、运营商等行业有了广泛应用。它在实时语音交互的基础算法层面,除语音识别、语义理解之外,集数据标注、训练于一体。平台能将AI的能力完美融入到客户应用场景中,许多人对此感到困惑,壹鸽智能语音客服机器人是如何进行语料整理标签挖掘分类的呢?下文就为大家详细的来介绍下。
一、语料
在“对话机器人”领域,语料通常指的是人与人、人与机器人之间交互时所产生的原始对话。
举个例子,假设你的企业需要为用户提供快递查询的客户服务。你的终端用户和你的运营人员,发生了如下一段对话:
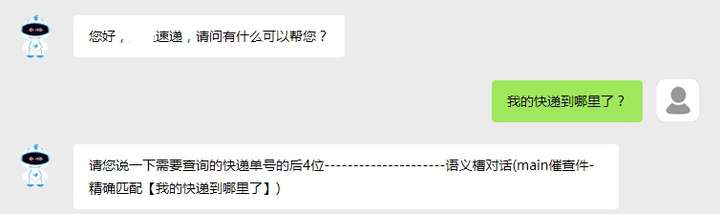
上述这段对话就是一段原始语料。 进一步地,在本文档使用“语料”一词的绝大多数场合,语料将特指为上述对话中终端用户所说的那一段话。
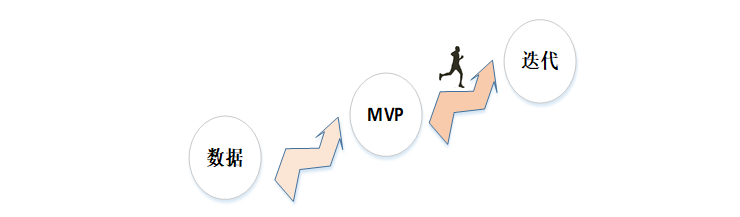
如果机器人已经上线, 开始服务用户, 就可以从平台的历史对话页面持续获得所有的用户历史交互语料。拿到数据之后,发现截止至今已有3千万这个量级的对话数据,就是客户和智能客服的聊天数据,然后发现每天可能有10万左右的新增消息。
我们要去看看数据,到底对话场景中发生了什么,用户在关注什么,从数据里面要去得到一些我们的先验知识。然后接着要从简单的MVP(最小可行产品)做起,再去从MVP迭代出更复杂的系统。
二、标签库概述
用用户的文本信息构建一个基础版本的用户画像,大致需要做以下这些事:
- 1、把所用的非结构化文本,去粗取精,保留关键信息,构建高质量的标签库。
- 2、根据用户口述文本,把标签传递给用户。
- 3、定期更新。
一个挖掘好的标签库,怎么衡量它的质量高低?
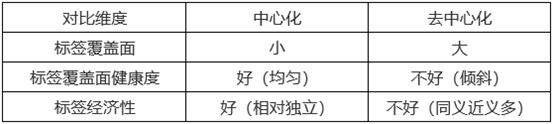
标签覆盖面:所用的标签在覆盖用户时,能够覆盖越多的用户越好,如果全部标签不能覆盖全部用户,就会有流量浪费。
标签健康度:量化标签平均覆盖用户的程度,单个标签的用户覆盖数量显然符合齐普夫定律,热门标签严重倾斜,这样倾斜的分布熵较小,但是好的标签库,其标签覆盖分布熵高,熵越高覆盖越均匀。
标签经济性:标签之间的语义相似性越小越好,因为一个标签占据用户兴趣向量中的一个维度,如果两个标签并没有提供两个不同的语义,却占据两个位置,那么这样的标签库显然性价比很低。
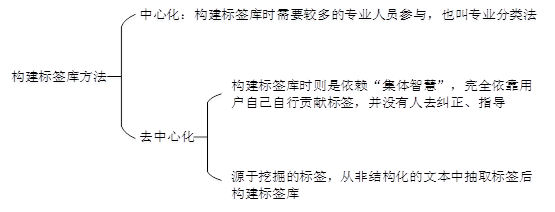
标签库的构建方法有,如下图所示:
两类标签对比如下图表所示:
因此,构建一个高质量的标签库,显然不能只依赖其中一种,而应该两者结合使用,如去中心的标签需要专业人员把控质量。
三、 标签挖掘方法
电话客服获取到的用户文本,是“非结构化”的,但是计算机在处理时只能使用结构化的数据索引检索,向量化后再计算。利用成熟的NLP算法分析可以得到如下信息:
关键词提取:最基础的标签来源,也为其他文本分析提供基础数据,常用TF-IDF和TextRank。
实体识别:省市地址、姓氏、物品、重量等,常用基于词典的方法结合CRF模型。
文本分类:将文本按照分类体系分类,用分类来表达粗粒度的结构化信息。
文本聚类:在无人定制分类体系的前提下,无监督地将文本划分成多个类簇也很常见,虽然不是标签,类簇编号也是用户画像的常见构成。
主题模型:从大量已有文本中学习主题向量,然后在预测新的文本再各个主题上的分布概率。主题模型也很常用,它其实也是一种聚类思想。主题向量不是标签形式,但也是用户画像的构成。
嵌入:也叫作Embedding,从词到篇章,都可以学习其嵌入表达。嵌入表达可以挖掘出字面之下的语义信息,并且用有限的维度表达出来。
四、 语料的用途
实现一个智能机器人有两个核心步骤:
第一,训练机器人的学习能力,让机器人学会理解和判断你终端用户的意图。
第二,评估机器人的学习效果。只有满足要求,才能“上岗”成为你的数字员工。
在上述两个步骤中,高质量的语料都起着至关重要的作用。
1) 高质量的语料可以让机器人学得更多、学得更好。
2) 高质量的语料可以让运营人员更容易评估机器人的效果,不会出现测试阶段和上线后效果差异巨大的情况。
如果你已经获得了一份高质量的语料, 那么, 在效果优化模块中,你可以将这份语料应用在如下几方面:
1) 短语挖掘
将语料传入短语挖掘来发现业务场景中常用到的一些实体。
2) 句子挖掘
将语料传入句子挖掘功能来发现业务场景中的知识点、相似说法。
3) 相似说法学习
将语料传入相似说法学习, 来审核待定相似说法,丰富机器人的知识。
4) 模型评测
对这份语料进行标注并传入模型来评测模型效果。利用评测的结果,来决定是否让机器人“上岗”服务。
关于标签挖掘的介绍就到这了,壹鸽后续也将会为大家带来更多相关的技术讲解,敬请期待吧!