基于AVS-M和DM642视频服务器的研究
2007/09/13
1 引言
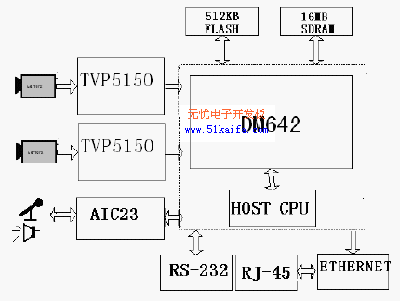
图1 IMlab6421硬件原理框图
3 软件设计
DSP嵌入式程序受硬件资源的限制,对程序流程和数据组织需要从硬件资源和代码运行效率上做仔细的考虑。通过分析AVS-M编码器的程序流程,借助实验中积累的经验,本文给出了AVS-M编码器的优化方案,主要介绍Cache性能优化、存储空间的分配以及CPU与DMA的并行性设计等。
3.1存储结构及CACHE性能优化
(1)存储结构:DM642的存储器系统由片内内存L1、L2和片外外存两部分组成,L1,L2和片外SDRAM构成了整个存储器系统的三级层次结构,如图2所示。其中,片内内存采用两级缓存结构,第一级由L1P和L1D组成,L1距离DSP核最近,数据访问速度最快,只需一个时钟周期,只能作为不能寻址的Cache使用。第二级L2是一个统一的程序/数据空间,可以整体作为SRAM映射到存储空间,也可以整体作为第二级Cache,或是二者按比例进行组合。第三级是片外外存,一般由SDRAM构成。L1Pcache大小为16KB,直接映射,每行大小32
字节;L1D cache大小16KB, 2路映射,每行大小64 字节。L2是L1和外存储器的中间层,容量较大有256KB,访问速度较慢,根据
L2 配置为Cache 或SRAM 的不同选择,访问速度需8个或6个时钟周期。片外存储器容量很大但访问速度很慢,一般都会远远大于 8 个时钟周期。
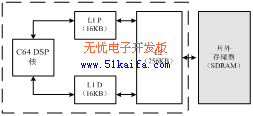
图2 三级存储系统
(2)CACHE性能优化:要优化Cache的使用性能需了解Cache的具体结构,如Cache容量、行大小、组相联数等。下面总结了一些优化Cache性能的方法:合理配置L2;合理布置程序代码段和数据段的内存布局,为防止有效代码、数据在缓冲存储器中相互排挤,应尽量把顺序执行的代码、同时使用的数据放在相互邻接的物理空间当中;若函数模块和数据包含在一个循环中,循环体的大小应和Cache的容量相吻合,以便能把整个循环体全部放入Cache中。为了提高Cache中数据的重复利用率,把数据操作构成一条数据处理链,链中的下一级操作就能直接使用上一级操作留在Cache中的数据。此外还可以根据Cache行数据宽度信息调节数据在物理内存中的存放位置,从而利用数据预取增加Cache的命中率;挖掘L1D的不命中流水处理能力,加速待使用数据的读入速度;通过合理的数据填充策略,避免同一时钟周期对相同存储体的读写操作将造成存储器的存取冲突。
3.2存储空间的分配
在DSP上由于内存空间有限,需要合理分配内存空间,这对于程序的运行效率十分重要。使用的一个原则是:应尽量把数据和代码放入片内存储器。因为外存比CPU工作的速度要慢很多,如果用CPU来处理访问外部存储器的工作,大量时间将浪费在存取等待上。
DM642的L2片内存储器可以配置为SRAM或Cache。由于编码器的数据流程是有规律的,因此我们考虑用程序控制DMA控制器来进行内存和外存之间的数据交换,这样比硬件自动地来处理效率要高。
由于片内存储器容量的限制,不可能将编码器的所有数据都放入片内存储器。原始图像和重构图像是无法完全放到片内存储器中的。事实上,没有必要将这些数据放在片内,因为编码器的处理过程是以宏块为单位的,我们只需要在片内维护一个宏块的数据结构,CPU访问这些数据进行计算。每编码一个宏块的时候把该宏块需要的数据从外存调入内存,填到相应的这些数据结构中。利用DM642提供的QDMA机制,CPU发出QDMA请求后就可以继续对其它数据进行计算,由DMA负责将数据从外存调到内部存储器。因此如何设计使CPU与DMA之间协调工作很重要,本文2.3部分将详细讨论这个问题。
需要注意的问题是当前宏块编码过程中需要用到前面编码已经获得的一些信息。参考代码中是保留所有宏块的编码信息,这样的做法是不适合DSP实现的,需要的存储空间太大,片内存储器无法容纳。实际上编码当前宏块只需要参考它上面和左面的宏块。因此设计编码器中各模块的局部数据结构如图3所示。该数据结构保留上面一行的值和左边宏块的值,每编码完一个宏块,确定当前宏块的信息后更新这些缓冲区,这些数据可以放在L2中,不用访问外存。而且实验证明用来维护这样的数据结构所需要的计算时间很小。

图3 模块的局部数据结构
经过优化的程序和常用的数据结构的大小可以放在L2中。所以按照上面的分析将L2配置为256KBSRAM,将程序代码段(.text)、变量初值表(.cint)、常量字符串(.const)、全局变量静态变量(.bss/.far)、堆栈段(.stack)等放入L2SRAM当中,全局堆(.sysmem用于动态存储器分配)置于外部存储器。表1总结了编码器所要用到的存储空间分配情况。
表1编码器存储空间的分配
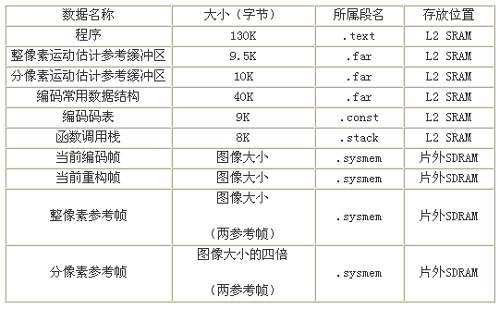
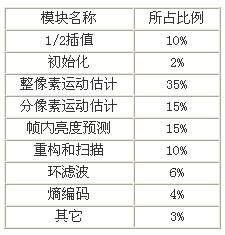
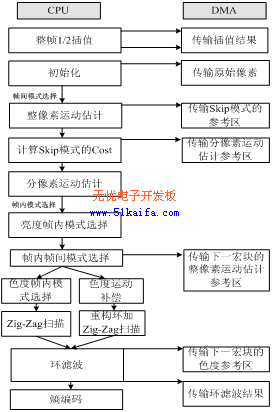
图4 CPU与DMA并行工作
只依靠上面这些方法进行优化,视频压缩还不能达到实时要求,还需要进行算法级优化,以及对编码器中各个模块进行程序代码级的优化。常通过采用内联函数、软件流水、线性汇编优化等方法,以及合理使用针对视频处理而设计的特殊指令集,充分利用DM642内部的并行计算单元,提高了程序的运行速度。由于篇幅有限,对这些优化方法本文不再重点论述。
4 .结论
结合AVS-M视频压缩处理流程的特点,本文完成了一个基于DM642平台的编码器的设计与实现。通过对编码流程的合理安排使得CPU能与DMA控制器并行工作,CPU不用等待数据,需要的数据已经被DMA调到内存中。实验表明通过系统级优化、程序级优化、汇编级优化、算法级优化等优化之后,基于这款视频服务器(实物图见图5),能达到2路CIF352x288格式实时视频压缩,以及音频实时编码、解码处理,且图像主观效果及音频效果良好。
本文创新点是:把具有自主知识产权的数字音视频编解码技术标准第七部分(AVS-M)应用于视频服务器的视频压缩,目前市场上还没有采用此压缩标准的产品,此产品具有极高得性价比,采用此压缩标准还可以避免产品产业化之后知识产权之争,具有很好的应用前景。

图5IMlab6421视频服务器实物图
| 视频监控标准化现状 2007-09-12 |
| 北京V2科技有限公司总裁杨丹专访:V2未来是可视的 2007-09-11 |
| 纵观IP视频监控 技术成熟度有待提 2007-09-11 |
| 客服呼叫中心进化版:视频互动客服系统 2007-09-10 |
| 新兴“遥现”技术:视频会议枯木逢春 2007-09-07 |