中英双语语音合成系统的研究
陈建宇、杨真 2008/08/01
摘要:本文首先简要介绍了语音合成概念,然后详细介绍了语音合成系统的核心,包括三个模块:文本分析模块、韵律控制模块和语音合成模块;接着介绍了用Microsoft speech SDK5.1制作一个中英双语音阅读器的过程,解决了Microsoft speech SDK5.1不能中英文混读的问题。
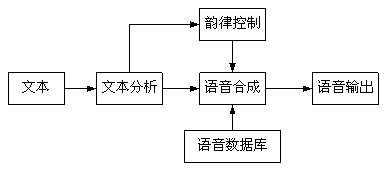
图1 语音合成系统结构示意图
2.1文本分析模块
语音合成系统首先处理的是文字,也就是它要说的内容。文本分析的主要功能是使计算机能从这些文本中认识文字,进而知道要发什么音、怎么发音,并将发音的方式告诉计算机。另外,还要让计算机知道,在文本中,哪些是词,哪些是短语或句子,发音时应该到哪里停顿及停顿多长时间等。其工作过程可以分为三个主要步骤:
(1)将输入的文本规范化。在这个过程中,要查找拼写错误,并将文本中出现的一些不规范或无法发音的字符过滤掉。
(2)分析文本中词或短语的边界,确定文字的读音,同时分析文本中出现的数字、姓氏、特殊字符、专有词语以及各种多音字的读音方式。
(3)根据文本的结构、组成和不同位置上出现的标点符号,确定发音时语气的变换以及不同音的轻重方式。
最终,文本分析模块将输入的文字转换成计算机能够处理的内部参数,便于后续模块进一步处理并生成相应的信息。
2.2韵律控制模块
早期的韵律生成方法均采用基于规则的方法。目前,基于规则的方法仍然被认作是行之有效的方法,大部分汉语语音合成系统依然采用这种方法。最近,通过神经网络或统计驱动的方法进行韵律生成已获得成功的应用。其实现步骤是:首先设计或收集一个包含大量语音和文本信息的数据,然后建立一个训练模型,并用从数据库中提取出的韵律参数对模型进行训练,通过训练而得到最终的韵律模型。
2.3语音合成模块
系统产生的合成语音是通过一个声学模块来具体实现的。早期语音合成系统的声学模型多是通过模拟人的口腔的声道特性来产生的。其中比较著名的有Klatt的共振峰(Formant)合成系统,后来又产生了基于LPC、LSP和LMA等声学参数的合成系统,这些都可以归结为参数合成系统。使用这些方法建立声学模型的过程是:首先录制声音,这些声音涵盖了人发音过程中所有可能出现的读音;然后,提取出这些声音的声学参数,并整合成一个完整的音库。在发音过程中,首先根据发音需要从音库中选择合适的声学参数,然后根据从韵律模型中得到的韵律参数,通过合成算法产生语音。参数合成方法的优点是其音库一般较小,并且整个系统能适应的韵律特征的范围较宽,但其合成语音的音质却往往受到一定的限制。
近10年来,采用波形拼接(PSOLA)合成语音的方法越来越被广泛应用。这种方法的核心思想是直接对存储于音库的语音运用PSOLA算法进行拼接,从而整合成完整的语音。
3.中英双语阅读器
3.1 Microsoft Speech SDK 5.1简介
Microsoft Speech SDK5.1是微软中国研究院推出的支持中文语音应用程序开发的工具包。它采用了COM标准开发,底层协议都以COM组件的形式独立于应用程序层。因此,在实现特定语音应用系统时,需考虑系统的功能实现和界面控制,不必考虑复杂的语音技术的实现算法,极大地降低了开发语音应用系统需要的代码量,从而为二次开发提供方便快捷的途径,并提供了系统的可扩展性和可维护性。它包括微软连续语音识别引擎(Microsoft
continuous speech recognition engine)和微软串联语音合成引擎(Microsoft
concatenated speech synthesis engine(也称TTS引擎)。利用提供的工具、信息、例子、SAPI5.1引擎和应用,用户可以方便地开发包含语音识别和语音合成功能的应用程序。这个版本的开发包含有一系列支持COM的语音自动化接口。自动化接口使得面向对象(Object-Oriented)开发方法终于在语音开发中得到了支持。Microsoft
Speech SDK5.1可在微软网站(http://www.Microsoft.com/downloads/details.aspx?familyid=5e86ec97-40a7-453f-b0ee-6583171b4530&displaylang=en)
免费下载。下载Microsoft Speech SDK5.1以及一个支持中英文的Language Pack,并按先后顺序分别安装。
3.2 新建工程并建立引用
新建工程后,单击工程―>引用,然后单击浏览按钮到程序文件夹\CommonFiles\Micro _softShared\Speech,选中Sapi.dll并单击确定,可看到“Microsoft
Speech Object Library”被添加到可使用的引用列表。为了使用slider控件和CommonDialog控件,单击工程―>部件,在弹出的对话框中选择“Microsoft
Windows Common Controls 6.0”和“Microsoft Windows Common Dialog
Control 6.0” ,这样所需要的控件就添加在了工具箱中。
3.3建立用户界面并设置相应属性
首先建立一个窗体,命名为Form1,作为启动窗体,将其Caption命名为“中英双语阅读器” 。在Form1中添加四个Frame控件,将它们的Caption分别命名为“请输入阅读的文档”
、“格式选择” 、“文件选择”和“播放控制” 。在Frame1添加一个TextBox控件,将其命名为MainTxtBox,用于输入文本。在Frame2添加四个Label控件,将它们的Caption分别命名为“语言:”
、“速度:” 、“音量:”和“格式:” ;两个ComboBox控件,分别命名为VoiceCB和FormatCB,用来选择阅读的语言和输出声音的格式;两个Slider控件,分别命名为RateSldr和VolumeSldr,分别控制阅读的速度和音量。在Frame3添加四个Label控件,将它们的Caption分别命名为“Open”
、“Clear” 、“Save”和“Close” ;添加四个commandButton控件,将它们分别命名为“OpenBtn”
、“ClearBtn” 、“SaveTxtBtn”和“CloseBtn” ,将它们的Caption分别命名为“打开(O)”
、“清除(L)” 、“保存(T)”和“关闭(C)” ,分别用来打开要阅读的文件、清除MainTxtBox中的内容、保存MainTxtBox中的内容和关闭中英文阅读器;在Frame4添加四个Label控件,将它们的Caption分别命名为分别“Speak”
、“Pause” 、“Stop”和“Save” ;添加四个commandButton控件,将它们分别命名为“SpeakBtn”
、“PauseBtn” 、“StopBtn”和“SaveWavBtn” ,将它们的Caption分别命名为“朗读(R)”
、“暂停(P)” 、“停止(S)”和“保存(W)” ,分别用于控制朗读过程的开始、暂停、停止和保存声音(WAV)文件。最后再添加一个CommonDialog控件,将其命名为ComDlg,用来调出“公共对话框”。设置完成的界面如图2所示。
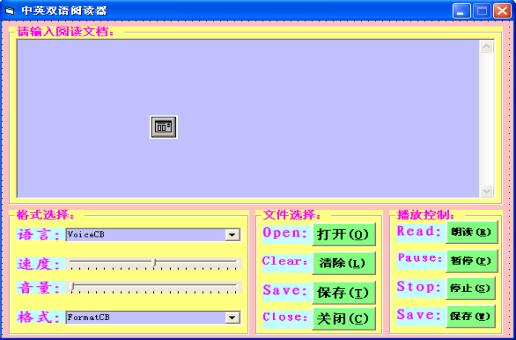
图2 中英文阅读器的界面
3.4 中英双语阅读器的算法原理
(1)中英双语阅读器核心技术的解决方案
本论文要制作的中英双语阅读器的语音库是引用Microsoft Speech SDK5.1的语音库。由于Microsoft
Speech SDK5.1的语音库在阅读时存在的很多的问题,因此我在制作中英双语阅读器时做了一些改进,使其有更好的阅读效果。
中英混读功能
中英混读功能是本阅读器最重要的功能,也是本研究要解决的核心问题。中英混读功能调用了Microsoft Speech
Object Library中的两位朗读者,中文时是Microsoft simplified Chinese,英文时是Microsoft
Sam。根据要阅读的文本实时地调用阅读引擎,达到了中英混读功能。主要原理是:
Step1:检测第一个字母设定初始阅读引擎和标志;
Step2:逐一检测每一个字符,并付给字符串str;
Step3:检测到不同种语音的字符时,调用阅读函数读出str,清空str并转换阅读引擎和标志;
Step4:检测是否到了文本的末尾,不是的话就转到Step2;
Step5:调用阅读函数读出str;
Step5:结束。
阅读各种号码的能力
Microsoft Speech SDK5.1的语音库在阅读时出现了很多问题,其中一个是当遇到一串数字时只能读成一个整体的数,比如“430074”它会读成“四十三万零七十四”
,这个在有的时候是正确的,但有的时候这个读法有是错误的,比如“武汉邮科院烽火科技学院的邮政编码是430074” ,根据人们的习惯“430074”就应该读成“四三零零七四”
,而不是“四十三万零七十四” 。类似的还有电话号码、传真等。解决这个方法是:当遇到数字时,就检测字符串str,当字符串中有“电话”
、“号” 、“码” 、“传真”时,就在数字后面添加空格,这样就能实现这样数的读法。
电子邮箱地址的读法
有时候要读到某人的电子邮箱地址,比如“我的电子邮箱是yujianchen@163.com”,应该读成“y u j
i a n c h e n @ 1 6 3 . com” ,而让阅读器会阅读时,“yujianchen”会一起读出,“@”不能读出,“163”读成“一百六十三”
,“.com”读成“点com” ,就最后一处读法是正确的,其他的都是错误的。怎样解决这个问题呢!这个不像电话号码那样直接检测数字前面有没有电话号码等字样,有的话就在数字后面加空格,因为一般的电子邮箱地址都即包含字母和数字,有的甚至还有文字,这样就会有引擎的转换,电子邮箱地址就不能在一个字符串里,因此不能像上面的(2)那样处理。经思考,得到了以下的解决方法:当遇到“邮箱”或者“电子邮箱”时,后面的字符之间都添加空格直到“.”为止。
网址的读法
网址会经常出现在文章中,根据测试,Microsoft Speech SDK5.1在读网址的时候不论是英文读法还是中文读法都是错误的,一般都是“/”读不对,如果没有改进,中英双语阅读器也是错误的,它把“/”读成了“除以”
。这个问题的具体解决办法是:先检测“mainTxtBox”中是否出现“http:”或者“www.” ,如果有的话,就检测当前字符是否为“字母”
、“数字” 、“.” 、“/”或者“:”(一般网址都是由这些字符组成的),如果是“:”或者“/” ,就用逗号来代替(也可以用空格来代替,只是这样的节奏感没有用逗号代替好);如果是数字,就在数字后面加空格;其他的字符就直接加到字符串上。这样改进后的读法就跟人们平时阅读时差不多了,不足之处是数字的读法是英文的。
(2)中英双语阅读器流程图
由于Microsoft Speech Object Library中,自带了四位朗读者:Microsoft simplified
Chinese、Microsoft Mary、Microsoft mike和Microsoft Sam四种。所以当选择其中的任何一位时,VB将自动的调用该说话引擎读出MainTxtBox中的字符。而Microsoft
Speech SDK5.1在朗读中英混合文本时,若使用中文引擎,对于英文单词只能将其包括的各个字母逐一朗读出来;若使用英文引擎,汉字就将被跳过,这样就失去了其本来的意义。“中英文混读”在这方面进行了改进,在语音朗读过程中提前判断将要处理文本的类型并且依据系统返回的消息,实时在中英文引擎之间进行切换,从而实现了真正的中英文朗读。
实现中英文文本朗读是中英双语阅读器的主要功能,其流程图如图3所示。
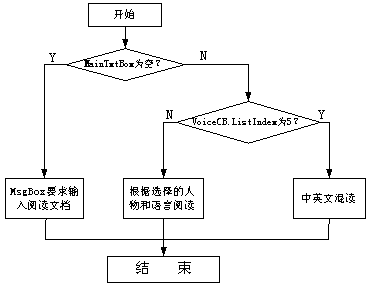
图3 中英双语阅读器流程图
(3)中英文混读算法流程图
如前所述,Microsoft Speech SDK5.1不能真正地进行中英文混合文本的朗读。我设计的中英文混读程序就要实现真正地进行中英文混合文本的朗读。该程序利用Microsoft
Speech SDK5.1自带的两位阅读者Microsoft simplified Chinese和Microsoft
Sam,根据判断当前字符,中文的调用Microsoft simplified Chinese,英文的调用Microsoft
Sam,这样就实现了中英文混合文本的朗读。具体的解决方案是:依序处理文本中每个字符,判断字符中含有的中英文类型,若类型与前一字符相同则添加至中间变量,否则朗读中间变量文本并保存当前位置,接着切换引擎。文本朗读结束,发出EndStream消息,从当前位置继续循环。其流程图如图4所示。
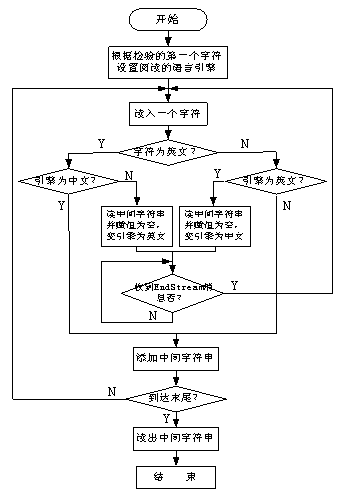
图4 中英文混读程序流程图
4 结束语
语音技术是一门新兴的学科,同时又是综合性的多学科领域和涉及面很广的交叉学科,是目前发展最为迅速的信息科学研究领域中的一个。Microsoft
Speech SDK5.1在朗读中英混合文本时,用中文引擎,对于英文单词只能将其包括的各个字母逐一朗读出来;用英文引擎,汉字就不能读,这样就失去了其本来的意义。中英双语阅读器在这方面进行了改进,实时在中英文引擎之间进行切换,从而实现了真正意义上的中英文朗读,这是本研究最大的创新点。同时根据Microsoft
Speech SDK5.1在阅读是出现的错误,对其进行了一些改进,包括电话号码、邮政编码等特殊数字、电子邮箱和网页地址的读法,使得阅读的效果更好,更符合现实中人们阅读的习惯。中英双语阅读器还有一个创新点是具有录音功能,也就是可以将文本文档转化为Wav格式保存,之后就可以用别的播放器播放,很方便。
但是不得不承认,Microsoft speech SDK5.1还存在着很多问题,比如说阅读时的流畅度和可懂度都有待提高。要真正实现计算机能够象人一样的说话,和人类自由地进行交谈,仍然需要假以时日,还有大量的研究工作要去做。
参考文献:
【1】黄南川,邓振杰,王嵬嵬.语音合成技术的研究与发展.华北航天工业学院学报,2002,12(3):37~39.
【2】李远志,李浮滨.语音合成技术在信息服务应用的前景分析.现代情报,2002,(2):106~107
【3】王卫华,陈卫东等.用Microsoft Speech SDK实现语音识别和语音合成.电子技术,2000,11.
【4】俞振利,程伯中.基于语音生成和发音模型的语音合成新方法的探讨.声学学报,2000,25(5):455~461
【5】罗三定,贾建华.基于波形音频段处理的中文语音合成研究.电脑与信息技术,2002,
作者:陈建宇、杨真 武汉邮科院烽火科技学院
作者简介
陈建宇,男,1982年出生,浙江温州人,武汉邮电科学研究院2006届研究生,主要研究方向是数字通信。
通信地址:湖北省武汉市洪山区邮科院路88号武汉光迅科技股份有限公司开发二部
杨真,男,湖北人,武汉同博科技有限公司研发部,主要从事研发管理。
电子工程专辑
| 语音合成技术开启后阅读时代 2008-05-14 |
| 有关语音自动化的十大常见误区 2008-05-06 |
| 科大讯飞总裁刘庆峰:语音市场进入爆发期 2008-01-04 |
| 身边的“智能”生活 2007-12-28 |
| 语音IM在带宽方面无需担忧 2007-12-24 |