
基于VoiceXML的语音应用系统开发
2008/10/30
一、概述
图一、VoiceXML应用和WEB应用的比较
下图(图二)展示了基于VoiceXML的语音应用系统的基本架构:
文档服务器(WEB Server):用于存放VoiceXML脚本文件(或者根据由VoiceXML
Server发过来了HTTP请求自动生成VoiceXML脚本),和事先录制好的音频文件等一切有关的文档。 VoiceXML
Server通过HTTP请求从该文档服务器获取各种需要的文件。
VoiceXML 服务器(VoiceXML Gateway):用于接收和识别用户的输入,解释和执行VoiceXML脚本文件,并把结果转换成语音输出给用户。它一般具备下列组件:VoiceXML解释器组件(VoiceXML
Browser),呼叫控制组件(CCXML Browser),自动语音识别组件(ASR),语音合成组件(TTS)等。这些组件共同组成了VoiceXML的解释和执行平台。
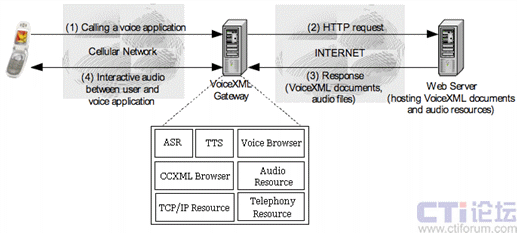
图二、VoiceXML应用系统架构
和互联网用户通过键盘输入某个WEB页面的地址(URL)来访问WEB应用类似,VoiceXML用户通过电话或者VoIP终端拨打某个应用对应的电话号码来访问该应用程序(图中的步骤1)。VoiceXML服务器收到用户的呼叫后,根据用户拨打的号码去文档服务器查找对应的VoiceXML文件(图中的步骤2),通过HTTP请求把文件下载到本机执行,根据特定应用的需要,VoiceXML服务器可能会发出多个HTTP请求获取和应用有关的其他文件,比如需要播放的语言文件等(图中的步骤3)。然后由
VoiceXML解释器组件( VoiceXML Browser)解释和执行VoiceXML脚本语言并把结果转换成语音传送给用户(图中的步骤4)。在执行过程中,用户可能需要通过语音和VoiceXML服务器进行交互,比如菜单选择或者对查询结果进行过滤等。VoiceXML服务器通过呼叫控制组件(CCXML
Browser),自动语音识别组件(ASR),语音合成组件(TTS)来实现这些交互。
在VoiceXML系统中有两种形式语音的输出: 机器合成语音(TTS)和事先录制好的语音文件。
TTS ( Text-To-Speech) : 是由机器把文本转换为数字语音格式,这种声音听起来会感觉有些机械和不自然,但是输出内容灵活,不受任何限制。
事先录制好的语音文件: 和TTS相比听起来更自然,但是内容受限制。在实际应用中往往把二者结合起来。
VoiceXML系统中的输入也有两种形式: 自动语音识别 (ASR) 和双音多频键盘音(DTMF)。
ASR (Automatic Speech Recognition) 是指计算机把用户的语音自动识别成文字信息,便于计算机的进一步处理,从而使得用户可以通过自然语言来控制计算机的执行。
DTMF (Dual Tone MultiFrequency) 则是用户可以通过电话的按键进行输入。
三、VoiceXML开发示例
本文中的信息查询例子演示了一个简单的VoiceXML应用。该例子VoiceXML脚本中用到的所有的标签如表1所示,表2是该例子的源代码。图四是该例子的呼叫流程。首先是用户发起呼叫,应用程序通过计算机合成语音(TTS)告诉用户所有的选择项并等待用户的响应。用户的语音将由计算机根据语法标签

图四:信息查询例子呼叫流程图
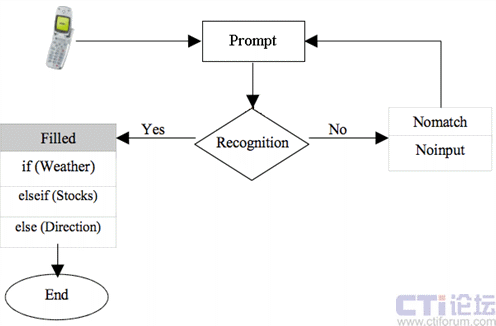
表 2. 信息查询例子源代码
该示例程序已经部署在http://evolution.voxeo.com。读者可以下列几个途径来执行该示例程序:
CTI论坛编辑
| Voxeo VoiceObjects 统一自服务提高满意度 2009-09-23 |
| Voxeo携Prophecy10高度亮相SpeechTEK2009 2009-09-03 |
| 拥有中文TTS的Prophecy IVR语音平台 2009-08-17 |
| Voxeo发布开源的电话“云计算”服务平台 2009-08-12 |
| 自助式语音平台开发利器Prophecy Platform 2009-08-03 |