使用数据采集,建立有利可图的客户关系
胡俊(编译) 2002/02/01
如果你已经建立了客户信息和市场的数据仓库,现在你该如何使用数据仓库中的数据?CRM帮助企业提高他们与客户相互作用的收益;与此同时,企业通过个性化服务可以使这种相互作用显得更友好。为了使CRM获得成功,企业应该使产品和商业活动跟期望和客户相匹配,换句话说,就是要职能化惯例客户生命周期。
到目前为止,大多数CRM软件更多关注客户信息的组织和管理的简单化。这些软件(只能称为操作性CRM软件)关注于创建一个客户数据库,这个DB提供了客户与企业关系的一致性描绘并用专门的应用程序来提供这些信息;这些软件包括SFA,客户服务程序,在这些软件中企业可以“touch”到客户。
然而,这些客户信息的绝对容量和日益复杂的与客户的相互作用将数据采集推倒了促使客户关系更有意义的最前端。数据采集是通过使用数据分析和数据建模的技术来发现数据之间的趋势和关系的过程,它可以用来理解客户希望获得什么,还可以预测客户将要做什么!数据采集可以帮助你选择恰当的客户并将注意力集中在他们身上,以便为他们提供恰当的附加产品;也可以帮助你辨别那些客户打算与你“分手”。由于可以提高以最好的方法响应个性化需求的能力,并且可以通过恰当的分配资源来降低成本,这会导致收入的增加。使用了数据采集的CRM应用程序被称为分析性CRM软件。下文将进一步描述ACRM的特征,并展示怎样使用ACRM来更有效的管理客户生命周期。
数据采集
数据采集中最基本、最简单的分析步骤就是描述数据。例如,你能够概述数据的静态属性,使用图表真实地回顾数据并注意你的数据中字段的值的分配。但是数据描述并不足以提供行动计划,你必须用从已知结果中确立的模式来建立预测性模型然后用其它的方法对它进行测试。一个好的模型决不该被真实情况所困惑(地图并不是真实的路的精确完美的反映),但是这个模型能够用来指导你理解你的业务。
数据采集可以用来对问题进行归类并逆推问题。在问题归类方面,你可以预测问题属于那一类,例如某一个人是否有良好的信用风险或者几个提议中哪一个最可能被接受。在逆推问题方面,你可以测定一些数据,如对某一个提议的响应的最大概率。数据采集也常常用来识别客户的特征,并按照相似性为(如购买特殊的产品)对客户进行分割归类。
再一次定义CRM
在对CRM的广泛理解中,最简单的含义就是:管理所有的与客户的相互作用。在实践中,这需要在客户关系的各个阶段使用与客户相关的信息来预测与客户的相互作用。我们将客户关系的各个阶段定义为客户生命周期。
客户生命周期包括三个阶段:
如果你已经将它结合在OCRM中或者作为一个独立的应用程序来实施,数据采集可以在每一个阶段都提高企业的收益。
通过数据采集获取新的客户
在CRM中的第一步是识别潜在客户然后将他们转变成真正的客户;下面将举例说明数据采集是如何帮助管理获取新客户的成本和改善这些活动的效果。
Big Bank and Credit Card Company(BB&CC)每年进行25次直接邮寄活动,每次活动都想一百万人提供申请信用卡的机会。“转化率”用来测量那些变成信用卡客户的比例,这是一个关于BB&CC每一次活动效果的百分比。
使人们填写信用卡申请仅仅是第一步,BB&CC必须判断申请是否有很好风险,然后决定接受他们成为自己的客户还是该拒绝他们的申请。更糟糕的信用风险的人可能比那些有较好信用风险的更容易被接受,对此不必感到惊奇。统计显示大约6%的人在接到邮寄后会提出申请,但他们中只有16%满足信用风险要求,结果邮件列表中的人大约有1%称为了BB&CC的新客户。
BB&CC的6%的响应率意味着每次活动中的100万人中仅有60000人对邮寄的请求产生响应。除非BB&CC改变这种建议使用信用卡的“恳求”的种类使用不同的邮件列表,用不同的方式影响客户,改变“恳求”的术语否则不可能获得超过60000人的响应。并且在6万人中只有1万人满足信用风险条件而成为客户。BB&CC面临的难题是更有效的影响那仅有的1万人。
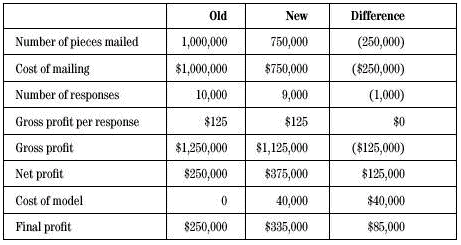
BB&CC的每份邮寄成本约1$,也就是说每次邮寄活动的总成本为$1,000,000。在接下来的两年里,那1万人将为BB&CC产生大约$1,250,000(每人约$125)的收益,结果从一次邮寄活动获得净利润为$250,000。数据采集可以改善这个回报率。尽管数据采集也不能精确的识别最后的那1万信用卡用户,但它可以帮助使促销活动的成本更有效。
首先,BB&CC发送了50,000个邮件做测试并仔细分析结果,使用决策建树建立预测模型来显示谁将对邮寄做出响应,用神经网络建立信用评分模型。接着BB&CC结合这两个模型来发现那些满足信用评定而且最可能对“恳求”产生响应的人群。
BB&CC运用这一模型再给邮件列表中剩下的950,000个人选择700,000发送邮件。结果显示:从这750,000(包括测试的50,000)件邮件中,BB&CC获得了9000份信用卡申请。换句话说,响应率从1%提高到了1.2%��增加了20%。虽然目标只达到了10000个中的9000个,但模型每有完美的,剩下的1000时无利可图的。
下面的统计数据的列表:
请注意,邮寄的纯利润增加了$125,000,甚至你扣除由于数据采集而产生的软件、硬件即人力资源方面的$40,000,纯利润还增加了$85,000。建模的投入转化成了200%的收益,这远远超过了BB&CC对这一项目的ROI要求。
提高现有客户的价值:通过数据采集进行搭配销售
Cannons and Carnations(C&C)是一家专门销售旧式迫击炮和大炮作为室外装饰的公司,它也卖大口径旧式手枪和步枪的收藏品作为室内装饰。C&C的产品目录手册被发送到大约1200万个家庭。
当客户打电话来下订单时,C&C使用Caller ID来识别打电话的人;另外C&C的代表还要求从产品目录手册的邮寄标签获得电话号码或客户编码。下一次,C&C的代表从数据库中寻找客户并处理订单。C&C有很好的机会进行搭配销售或者卖给订购者其它附加产品;但是C&C发现在第一次建议失败之后,代表向客户做出第二次建议时,客户可能愤怒的挂断电话而什么也不定购。的确存在一些客户愤恨任何搭配销售。
在世时数据采集之前,C&C一直在勉强进行搭配销售。没有模型时,做出恰当的推荐的几率为1/3。因为向一些客户做出了无法接受的建议,所以C&C希望对“不该推荐时决不做出推荐”这一点非常有把握。在实验中发现C&C的搭配销售的销售率增加不到1%;而C&C过去一直为这一点获利勉强进行搭配销售。
在实施数据采集之后,情形发生了戏剧性的改变;现在数据采集模型操纵数据。通过使用数据库和新订单中的客户信息,这会告诉客户服务代表应该推荐什么。C&C成功卖给了2%的客户一件附加产品,而且更重要的却没有得到客户的抱怨。
开发这种性能的过程与前面用来解决信用卡客户获得问题相似;和前面的情况相同,有两个模型是必需的。
第一个模型预测一些人是否为被建议买附加产品而感到不愉快。C&C通过简短的电话调查了解客户的法应如何。按照保守的计算方法,C&C将拒绝参与调查的人和对推荐购买附加产品反感的人均计算在内。随后,为了检验这种假设(将拒绝参与调查的人归入拒绝推荐的人),C&C向这些拒绝回答调查问题的人推荐附加产品;令人感到惊奇的是,他们并不拒绝打[诶销售,于是发现调查时没有根据的。这使BB&CC可以做出更多的推荐,并进一步提高收益。第二个模型用来预测哪些提议不会被接受。
总之数据采集帮助BB&CC更好地理解它的客户的需求。当数据采集模型被结合在典型的搭配销售的CRM活动中时,这些模型帮助BB&CC提高了2%的收益。
提高现有客户的价值:通过数据采集进行个性化服务
Big Sam’s Clothing 开发一个网站来补充它的商品目录。当你访问它的网站是,你首先会看到“Howdy Pardner”的欢迎词。然而,一旦你在该网站注册,Pardner就会变成你的姓名。如果已经有过Big Sam’s的订单纪录,它就会告诉你那些可能引起你的特殊兴趣的新商品。当你注意到一件特殊的商品如一件防水皮大衣时,Big Sam’s会建议在一此购买中需要补充的其它条目。
在Big Sam’s第一次将网站投放市场时,并没有什么个性化的内容,网站只是商品目录有效的在线翻版;但是却没有利用Web现存的销售机会。
数据采集迅速提高了Big Sam’s的网络销售。产品目录手册常常简单地按照用户挑选产品的类型对商品进行分组。然而在在线商店中商品分组可能是完全不同的,它常常以考虑内的商品补充条目为基础。网站特别的地方还在于:它不仅考虑你看到的条目,而且还考虑你的“购物篮”中的商品,结果就会产生更加客户化的推荐。
首先,Big Sam’s使用聚类(clustering)的方法来发现哪些商品时自然的分在一组中。有时一些聚类是十分明显的,如衬衫和短裤;一些聚类可能是令人惊奇的,如关于沙漠探险的书和医疗工具包。这些聚类用来在有人看到其中的一个产品使向他做出建议。
Big Sam’s接着建立客户剖析来帮助识别哪些会对经常添加在商品目录中的新商品感兴趣的客户。Big Sam’s所做的指引客户购买那些挑选出来的产品不仅仅带来销售的增加,而且巩固了客户关系。调查显示Big Sam’s被看作是一个衣物和装饰品方面可信赖的顾问。
为了扩大影响,Big Sam’s实施了一个应用程序来向客户发送Email,这些Email包含了由数据采集模型预测的会吸引客户的新产品信息。当客户将这个看作牵摄客户服务的例子时,Big Sam’s发现这是一个可以改善收益的程序。
个性化销售的努力为Big Sam’s带来了盈利:它在重复销售、每一客户的平均销售量和销售的平均范围等方面带来了一个重大的、可测量的提高。
保持上等(收益)客户:通过数据采集
几乎每一个公司在获取一个新客户所投入的成本都远大于保持一个上等客户的成本。KownServce(ISP,如中国的163)所面临的一个难题是,它每月经历每月8%的行业平均磨损(客户减少)率;这意味着如果他拥有100万客户,则每月会有8万的客户离它而去。替换这些客户的成本为每个200美金或者一共1600万,这也是着手磨损管理程序的主要动机。
KownServce要做的第一件事就是准备用来预测哪些客户会离开的数据。KownServce需要从客户数据库中选择变量并(可能)进行转换。KownServce的大多数用户是进行拨号连接,所以KownServce知道每一个客户连接到Web需要多长的时间。KownServce也知道客户计算机的传输的数据量、一个用户所用有的Email账号的数量、Email信息发送和接收的数量以及客户的账单历史。另外,KownServce还有客户拨号时提供的人口统计数据。
KownServce要做的第一件事就是需要识别哪些是“上等”客户。这并不是数据采集问题,而是通过计算得出的商业定义(如收益率或生命周期价值)。KownServce建立模型来剖析能带来收益的客户和不能带来收益的客户。KownServce不仅用这一模型来提高客户的保持力,还用它来识别哪些客户现在不能带来收益但将来却可以。
接着KownServce建立模型来预测哪些可以带来收益的客户会离开。在大多数数据采集问题中,决定如何使用哪些数据和怎样将现存数据结合起来是模型开发中最大的难题。例如:KownServce需要关注如每月使用的时间系列数据,模型中宁愿使用三个月中每月的平均数量而不采用原始的时间系列数据。KownServce也计算出三个月的平均数量的改变,并将它作为预测的依据。这些依据中一部分是非常好的,如下降的使用,它们是出现需要处理的问题的预兆;另外一些依据如服务请求的数量和它的平均数量的改变预示着客户满意度出现问题。
预测谁将出现离开是不够的。基于模型产生的结果,KownServce确定可能的计划和可以诱使客户留下的提议。例如一部分离开者由于超过固定费用下的可用量一大截的使用(上网)而需要支付次超过的得那一部分真实的费用;KownServce给这一部分用户提供较高费用的服务,但却包含更多的捆绑时间。也有一些客户被提议使用更多的磁盘空间来存放个人主页。KownServce建立模型来预测度一个特殊的用户需要提供更有效的提议。
总的说来,项目需要三个模型。一个模型用来确定离开用户,第二个模型用来选择可以带来收益的潜在的离开者来进行“饲养”,第三个模型为这些潜在的离开者匹配最适宜的提议。得到的结果是KownServce的客户离开率由8%下降到7.5%,这为KownServce每月减少获取客户的成本为$1,000,000。
KownServce发现自己的数据采集投资是有回报的它改善了客户关系,并且引人注目地提高了收益。
将数据采集运用到CRM中
为了为你的CRM系统建立良好的模型,有一些步骤你必须遵行。下面描述的两个数据采集过程模型与其它模型是相似的,不同之处仅在于在不同步骤中强调的重点而已。
紧记下面列表中的步骤,但数据采集过程并不是线性的你需要回复到前面的步骤是不可避免的。例如在“explore data”中进行的内容可能需要你增加新的数据到数据采集数据库中。你建立的初始模型可能提供一种洞察力,它会引导你增加新的变量。
有效的CRM中的数据采集的基本步骤为:
1. 定义商业问题(Define business problem)
2. 建立行销数据库(Build marketing database)
3. 研究数据(Explore data)
4. 为建模准备数据 Prepare data for modeling)
5. 建立模型(Build model)
6. 评价模型(Evaluate model)
7. 展开模型获得结果Deploy model and results
1. 定义商业问题 每一个CRM应用程序都有一个或多个商业目标,为此你需要建立恰当的模型。根据你特殊的目标如“提高响应率”或“提高每个响应的价值”,你将建立完全不同的模型。问题的有效陈述包含了测量你的CRM引用程序的成果的方法。
2. 建立行销数据库 二到四是组成数据准备的核心。他们花费的时间或努力比其他几步加起来还多。数据准备和模型建立之间可能反复进行,因为你从模型中学到新的东西,而这又要你修改数据。数据准备阶段无论如何也要占去全部数据采集过程的50%到90%的时间和努力。
你需要建立一个行销数据库,因为你的操作性数据库和操作性数据仓库常常没有提供你需要的形式的数据;此外,你的CRM应用程序还可能性干扰这个系统的快速、有效地执行。
在你建立行销数据库的时候,你好需要对它进行净化如果你想获得良好的模型,你必须有干净的数据。你需要的数据可能在不同的数据库中,如客户数据库,产品数据库以及事务处理数据库。这意味你需要集成巩固数据到单一的行销数据库中并且去除来之多个数据源的数据在值商的差异。没有恰当进行数据值差异的数据是质量问题的主要来源。在多个数据源中出现的较大差异主要在数据定义和使用的方法上。数据值的一些矛盾是很容易发现的,如同样的客户有几个不同的(不同的系统正在使用)的地址;但也有一些是很“狡猾的”,如同一个客户有不同的名字,更糟的是有不同的客户识别编码。
3. 研究数据 在建立良好的预测模型之前,你必须理解你使用的数据的含义。通过聚集各种数据摘要(如平均值、标准偏离)和关注数据描述开始进行研究数据。你可能为多维数据建立交叉表格。
图像化和可视化工具是数据准备中的所必需的,但它们对数据分析的重要性却不能过分强调。数据可视化常产生导致新的洞察力和成功的内容。一些非常有用的普偏的数据显示是柱状图,它显示了数据值得分布情况。你也可以看到不同参数的二维获三维的散点图。这种增加第三变量的能力极大地提高了一些图形的可用性。
4. 为建模准备数据 这是建立模型之前的数据准备的最后一步。这一步中主要有四个主要的部分:
首先,你要为建立模型选择变量。理想情况是:将你拥有的所有变量加入到数据采集工具中,找到那些最好的预测。但在实际中,这是非常棘手的。其中一个原因是建立模型的时间随着变量得增加而增加。另一个原因就是盲目性,包括无关紧要的数据列被加入,却很少甚至不能提高预测能力。
下一步是从原始数据中构件新的预测依据。例如预测信用风险使用使用债务收入的比率而不是单独使用债务和收入作为预测依据的变量可以产生更准确的结果并且更容易理解。
接着,你需要从数据中选取一个子集或标本来建立模型。即使你有许多数据;然而使用所有的数据会花费太长的时间或者需要买更好的硬件,但你并不愿意如此。使用恰当的随机挑选的子集并不会产生CRM问题的信息的不足。建立模型的两种选择为:使用所有得数据建立一个模型或者建立多个以数据标本为基础的模型;后者常常能帮助你建立更准确有力的模型。
最后,你需要转换变量,使之和你选定用来建立模型的运算法则一致。
5. 数据采集模型的建立 关于模型建立的需要记住的最重要的就是模型建立是一个迭代的过程。你需要研究可供选择的模型,从中找到过解决你的商业问题最有用的。在你探究一个好的模型过程中获悉的知识或许要求你回头修改你正在使用的数据甚至修改你的问题的陈述。
大多数CRM应用程序都给予一种叫做被监督学习的协议。你开始使用客户信息,而且要求产生的结果是已知的。例如,你有来自以前的邮件列表的历史数据,它与你现在使用的数据非常相似。或者,你可能不得不进行邮寄测试来确定人们对一个提议的响应如何。你将数据分为两组,使用第一组来培养建立或评估你的模型,接着使用第二组数据来测试模型。当培养和测试周期完成之后,模型也就建立起来了。
6. 评价模型 评价模型结果的方法中,最可能产生评价过高的基准就是精确性。假设你有一个提议仅仅有1%的人响应。模型预测“没有人会响应”,这个预测99%是正确的,但那确实100%的无效。另一个常使用的基准“提高多少”,这用来衡量使用模型后完成的改进有多大,但是它并没有考虑成本和收入。所以最可取的评价基准是收益或ROI。
7. 将数据采集运用到CRM方案中 在建立CRM应用中,数据采集常常是整个产品中很小的但意义重大的一部分。例如:以数据采集为基础预测模式可能将各个领域专家的知识结合在一个很大的被许多类型的人使用的应用程序中。
数据采集被实际建立在应用程序中的方式由你的客户交互作用的本质所决定。你与客户的交互作用的两种方式:客户主动联系你(inbound)或者你主动联系他们(outbound)。这时数据采集展开的需求是完全不同的。
后一种方式的特征有你的公司所决定;因为联系活动是由你的公司发起,例如直接邮寄活动。结果,通过运用模型到你的客户数据库,你选择客户进行联系。Outbound商业活动的另一种类型是广告活动。这用情形下,你对由模型显示的具有良好前景的特征和你的广告可以影响的人的特征进行匹配。
在inbound事务中,如电话定购,Internet订购,客户服务呼叫等,应用程序必须实时响应;因此数据采集是内含在这种应用程序中的并且积极地做出推荐动作。
无论哪一种情形,在运用模型到新数据中你必须处理的一个关键问题是你在建立模型中的使用数据转换。如果在无论来自事务处理还是数据库的输入数据中包含了年龄、收入、性别字段,但是模型需要的年龄收入比率和性别已经改变为二元变量,因此你必须转换输入数据。当你想快速展开大量模型时,不费力的插入这些转换数据就变成了最重要的生产力因素。
结论
在当今市场上,客户关系管理的本质就是更有效地进行竞争。你使用你的客户信息来满足客户需求的效果越好,你就会获得更多的收益。操作性CRM需要分析性CRM,应为ACRM的核心就是预测性的数据采集模型。商业成功的途径需要理解客户和客户的需求,而数据采集正是它的基本指南。
本文来自SPSS的英文材料,文中的内容可以理解为ACRM的运用方式(另外两个为:认识什么是ACRM和ACRM的数据仓库得建立)。该公司提供发现客户期望和预测客户将要做什么的解决方案;这种方案位于CRM和BI的交接处。SPSS的解决方案集成并分析行销、客户和操作性数据,它为全世界垂直市场的以下行业提供解决方案:电讯、保健、银行、金融、保险、制造、零售业、市场研究等。
AMT 2002/02/01
| CRM难在哪里? 2002-02-01 |
| CRM所缺少的元素――感情 2002-02-01 |
| CRM的未来――CVM 2002-02-01 |
| 利用数据库营销赢得新顾客 2002-01-30 |
| 吸引目标消费者的工具――邮件营销 2002-01-30 |